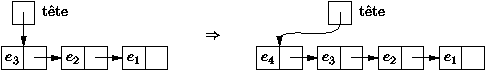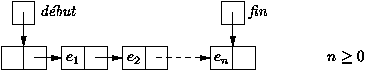Chapitre 3 Structures de données élémentaires
Dans ce chapitre, nous introduisons quelques structures utilisées de
façon très intensive en programmation. Leur but est de gérer un
ensemble fini d'éléments dont le nombre n'est pas fixé a
priori. Les éléments de cet ensemble peuvent être de
différentes sortes: nombres entiers ou réels, chaînes de
caractères, ou des objets informatiques plus complexes comme les
identificateurs de processus ou les expressions de formules en cours
de calcul ... On ne s'intéressera pas aux éléments de
l'ensemble en question mais aux opérations que l'on effectue sur cet
ensemble, indépendamment de la nature de ses éléments. Ainsi
les ensembles que l'on utilise en programmation, contrairement à
ceux considérés en mathématiques qui sont fixés une fois pour
toutes, sont des objets dynamiques. Le nombre de leurs éléments
varie au cours de l'exécution du programme, puisqu'on peut y ajouter
et supprimer des éléments en cours de traitement. Plus
précisément les opérations que l'on s'autorise sur les ensembles
sont les suivantes :
- tester si l'ensemble E est vide.
- ajouter l'élément x à l'ensemble E.
- vérifier si l'élément x appartient à l'ensemble E.
- supprimer l'élément x de l'ensemble E.
Cette gestion des ensembles doit, pour être efficace, répondre au
mieux à deux critères parfois contradictoires: un minimum de place
mémoire utilisée et un minimum d'instructions élémentaires
pour réaliser une opération. La place mémoire utilisée devrait
pour bien faire être très voisine du nombre d'éléments de
l'ensemble E, multipliée par leur taille; c'est ce qui se passera
pour les trois structures que l'on va étudier plus loin. En ce qui
concerne la minimisation du nombre d'instructions élémentaires, on
peut tester très simplement si un ensemble est vide et on peut
réaliser l'opération d'ajout en quelques instructions, toutefois
il est impossible de réaliser une suppression ou une recherche d'un
élément quelconque dans un ensemble en utilisant un nombre
d'opérations indépendant du cardinal de cet ensemble (à moins
d'utiliser une structure demandant une très grande place en
mémoire). Pour améliorer l'efficacité, on considère des
structures de données dans lesquelles on restreint la portée des
opérations de recherche et de suppression d'un élément en se
limitant à la réalisation de ces opérations sur le dernier ou le
premier élément de l'ensemble, ceci donne les structures de pile ou
de file, nous verrons que malgré ces restrictions les structures en
question ont de nombreuses applications.
3.1 Listes chaînées
La liste est une structure de base de la programmation, le
langage LISP (LISt Processing), conçu par John MacCarthy en
1960, ou sa version plus récente Scheme [1], utilise
principalement cette structure qui se révèle utile pour le calcul
symbolique. Dans ce qui suit on utilise la liste pour
représenter un ensemble d'éléments. Chaque élément est
contenu dans une cellule, celle ci contient en plus de
l'élément l'adresse de la cellule suivante, appelée aussi pointeur. La recherche d'un élément dans la liste s'apparente à
un classique ``jeu de piste'' dont le but est de retrouver un objet
caché: on commence par avoir des informations sur un lieu où
pourrait se trouver cet objet, en ce lieu on découvre des
informations sur un autre lieu où il risque de se trouver et ainsi
de suite. Le langage Java permet cette réalisation à l'aide de classes
et d'objets: les cellules sont des objets (c'est à dire des instances
d'une classe) dont un des champs contient une réference vers la
cellule suivante. La référence vers la première cellule est elle
contenue dans une variable de tête de liste. Les déclarations
correspondantes sont les suivantes, où l'on suppose ici que les
éléments stockés dans chaque cellule dont de type entier..
class Liste {
int contenu;
Liste suivant;
Liste (int x, Liste a) {
contenu = x;
suivant = a;
}
}
L'instruction new Liste (x, a) construit une nouvelle
cellule dont les champs sont x et a. La fonction Liste(x,a) est
un constructeur de la classe Liste (un constructeur est une
fonction non statique qui se distingue par le type de son résultat qui
est celui de la classe courante et par son absence de nom pour
l'identifier). L'objet null appartient à toute classe, et
représentera dans le cas des listes le marqueur de fin de liste. Ainsi
new Liste(2, new Liste (7, new Liste (11, null))) représentera
la liste 2,7,11. Les opérations sur les ensembles que nous avons
considérées ci-dessus s'expriment alors comme suit si on gère ceux-ci
par des listes:
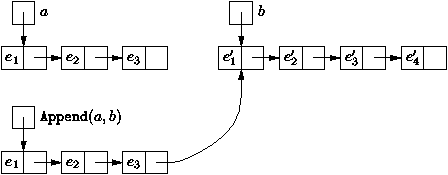
Figure 3.1 : Ajout d'un élément dans une liste
static boolean estVide (Liste a) {
return a == null;
}
La procédure ajouter insère l'élément x en tête de
liste. Ce choix de mettre l'élément en tête est indispensable
pour que le nombre d'opérations lors de l'ajout soit indépendant
de la taille de la liste; il suffit alors de
modifier la valeur de la tête de liste ce qui est fait simplement par
static Liste ajouter (int x, Liste a) {
return new Liste (x, a); // L'ancienne tête se retrouve après x
}
La fonction recherche, qui vérifie si l'élément x figure
bien dans la liste a, effectue un parcours de la liste pour
rechercher l'élément. La variable a est modifiée itérativement
par a = a.suivant de façon à parcourir tous les éléments
jusqu'à ce que l'on trouve x ou que l'on arrive à la fin de la
liste (a = null).
static boolean recherche (int x, Liste a) {
while (a != null) {
if (a.contenu == x)
return true;
a = a.suivant;
}
return false;
}
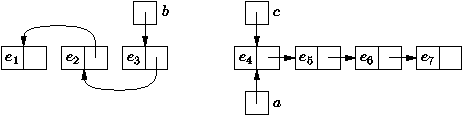
Figure 3.2 : Suppression d'un élément dans une liste
La fonction recherche peut aussi être écrite de
manière récursive
static boolean recherche (int x, Liste a) {
if (a == null)
return false;
else if (a.contenu == x)
return true;
else
return recherche (x, a.suivant);
}
ou encore
static boolean recherche (int x, Liste a) {
if (a == null)
return false;
else
return (a.contenu == x) || recherche (x, a.suivant);
}
ou encore encore (quoique non recommandé):
static boolean recherche (int x, Liste a) {
return a != null && (a.contenu == x || recherche (x, a.suivant));
}
Cette écriture récursive est systématique. pour les
fonctions sur les listes. En effet, le
type des listes vérifie l'équation suivante:
Liste = {Liste_vide} È
Element × Liste
|
où È est l'union disjointe et × le produit
cartésien. Toute procédure ou fonction travaillant sur les listes
peut donc s'écrire récursivement sur la structure de sa liste
argument. Par exemple, la longueur d'une liste se calcule par
static int longueur(Liste a) {
if (a == null)
return 0;
else
return 1 + longueur (a.suivant);
}
ce qui est plus élégant que l'écriture itérative qui suit
static int longueurI(Liste a) {
int longueur = 0;
while (a != null) {
++longueur;
a = a.suivant;
}
return longueur;
}
Choisir entre la manière récursive ou itérative est affaire
de goût. Autrefois, on disait que l'écriture itérative était plus
efficace car utilisant moins de mémoire. Grâce aux techniques
nouvelles de compilation (comme l'élimination des récursions
terminales), c'est de moins en moins vrai; de plus l'occupation
mémoire est, dans les ordinateurs d'aujourd'hui, une question
nettement moins critique.
La suppression de la cellule qui contient x s'effectue en
modifiant la valeur de suivant contenue dans le
prédécesseur de x: le successeur du prédécesseur de
x devient le successeur de x. Un traitement particulier
doit être fait si l'élément à supprimer est le premier
élément de la liste. La procédure récursive de suppression est
très compacte dans sa définition.
static Liste supprimer (int x, Liste a) {
if (a != null)
if (a.contenu == x)
a = a.suivant;
else
a.suivant = supprimer (x, a.suivant);
return a;
}
Une procédure itérative demande beaucoup plus d'attention.
static Liste supprimer (int x, Liste a) {
if (a != null)
if (a.contenu == x)
a = a.suivant;
else {
Liste b = a ;
while (b.suivant != null && b.suivant.contenu != x)
b = b.suivant;
if (b.suivant != null)
b.suivant = b.suivant.suivant;
}
return a;
}
Noter que dans les deux fonctions ci-dessus, on a modifié la liste
a, on ne peut donc disposer de deux listes distinctes l'une qui
contient x et l'autre identique à la précédente, mais ne
contenant pas x. Pour ce faire, il faut recopier une partie de
la liste a dans une nouvelle liste, comme le fait le programme
suivant, où il y a une utilisation un peu plus importante de la
mémoire. Mais l'espace mémoire perdu est récupéré par le glaneur de
cellules (GC) de Java, si personne n'utilise l'ancienne liste
a. Avec les techniques actuelles de GC à générations, cette
récupération s'effectuera très rapidement. Il faut donc noter la
différence avec un langage comme Pascal ou C, où on doit se préoccuper
de l'espace mémoire perdu, si on veut pouvoir le réutiliser.
static Liste supprimer (int x, Liste a) {
if (a != null)
return null;
else if (a.contenu == x)
return a.suivant;
else
return new Liste (a.contenu, supprimer (x, a.suivant));
}
Une technique souvent utilisée permet d'éviter quelques tests pour
supprimer un élément dans une liste et plus généralement pour
simplifier la programmation sur les listes. Elle consiste à utiliser
une garde permettant de rendre homogène le traitement de la
liste vide et des autres listes. En effet dans la représentation
précédente, la liste vide n'a pas la même structure que les autres
listes. On utilise une cellule placée au début et n'ayant pas
d'information significative dans le champ contenu; l'adresse de
la vraie première cellule se trouve dans le champ suivant de
cette cellule.
On obtient ainsi une liste gardée, l'avantage d'une telle
garde est que la liste vide contient au moins la garde, et que par
conséquent un certain nombre de programmes, qui devaient faire un cas
spécial dans le cas de la liste vide ou du premier élément de
liste, deviennent plus simples. Cette notion est un peu l'équivalent
des sentinelles pour les tableaux. On utilisera cette technique dans
les procédures sur les files un peu plus loin (voir page
X) . On peut aussi définir des listes
circulaires gardées en mettant l'adresse de cette première cellule
dans le champ suivant de la dernière cellule de la liste.
Les listes peuvent aussi être gérées par différents autres
mécanismes que nous ne donnons pas en détail ici. On peut
utiliser, par exemple, des listes doublement chaînées dans
lesquelles chaque cellule contient un élément et les adresses à
la fois de la cellule qui la précède et de celle qui la suit. Des
couples de tableaux peuvent aussi être utilisés, le premier contenu contient les éléments de l'ensemble, le second adrsuivant contient les adresses de l'élément suivant dans le
tableau contenu.
Remarque
La procédure ajouter effectue 3 opérations élémentaires. Elle
est donc très efficace. En revanche, les procédures recherche et
supprimer sont plus longues puisqu'on peut aller jusqu'à
parcourir la totalité d'une liste pour retrouver un élément. On peut
estimer, si on ne fait aucune hypothèse sur la fréquence respective
des recherches, que le nombre d'opérations est en moyenne égal à la
moitié du nombre d'éléments de la liste. Ceci est à comparer à la
recherche dichotomique qui effectue un nombre logarithmique de
comparaisons et à la recherche par hachage qui est souvent bien plus
rapide encore.
Exemple
A titre d'exemple d'utilisation des listes, nous considérons la
construction d'une liste des nombres premiers inférieurs ou égaux
à un entier n donné. Pour construire cette liste, on commence,
dans une première phase, par y ajouter tous les entiers de 2 à
n en commençant par le plus grand et en terminant par le plus
petit. Du fait de l'algorithme d'ajout décrit plus haut, la liste
contiendra donc les nombres en ordre croissant. On utilise ensuite la
méthode classique du crible d'Eratosthène: on considère
successivement les éléments de la liste dans l'ordre croissant et
on supprime tous leurs multiples stricts. Ceci se traduit par la
procédure suivante :
static Liste listePremier (int n) {
Liste a = null;
int k;
for (int i = n; i >= 2; --i) {
a = ajouter (i, a);
}
k = a.contenu;
for (Liste b = a; k * k <= n ; b = b.suivant){
k = b.contenu;
for (int j = k; j <= n/k; ++j)
a = supprimer (j * k, a);
}
return(a);
}
Remarque
Nous ne prétendons pas que cette programmation
soit efficace (loin de là!). Elle est toutefois simple à écrire,
une fois que l'on a à sa disposition les fonctions sur les listes.
Elle donne de bons résultats pour n inférieur à 10 000. Un bon
exercice consiste à en améliorer l'efficacité.
Exemple
Un autre exemple, plus utile, d'application des listes est la gestion
des collisions dans le hachage dont il a été question au chapitre 1
(voir page X). Il s'agit pour
chaque entier i de l'intervalle [0 ... N-1] de construire une
liste chaînée Li formée de toutes les clés x telles que h(x) =
i. Les éléments de la liste sont des entiers permettant d'accéder aux
tableaux des noms et des numéros de téléphone. Les procédures de
recherche et d'insertion de x dans une table deviennent des
procédures de recherche et d'ajout dans une liste. Ainsi, si la
fonction h est mal choisie, le nombre de collisions devient
important, la plus grande des listes devient de taille imposante et le
hachage risque de devenir aussi coûteux que la recherche dans une
liste chaînée ordinaire. Par contre, si h est bien choisie, la
recherche est rapide.
Liste al[] = new Liste[N-1];
static void insertion (String x, int val) {
int i = h(x);
al[i] = ajouter (x, al[i]);
}
static int recherche (String x) {
for (int a = al[h(x)]; a != null; a = a.suivant) {
if (x.equals(nom[a.contenu]))
return tel[a.contenu];
}
return -1;
}
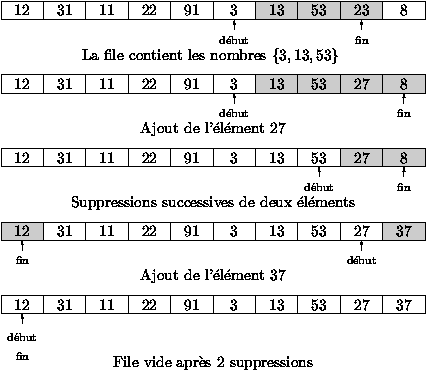
3.2 Files
Les files sont utilisées en programmation pour gérer des objets
qui sont en attente d'un traitement ultérieur, par exemple des
processus en attente d'une ressource du système, des sommets d'un
graphe, des nombres entiers en cours d'examen de certaines de leur
propriétés, etc ... Dans une file les éléments sont
systématiquement ajoutés en queue et supprimés en tête, la
valeur d'une file est par convention celle de l'élément de tête.
En anglais, on parle de stratégie FIFO First In First Out, par
opposition à la stratégie LIFO Last In First Out des piles.
De façon plus formelle, on se donne un ensemble E,
l'ensemble des files dont les éléments sont dans E est noté
Fil(E), la file vide (qui ne contient aucun élément) est F0, les
opérations sur les files sont vide, ajouter, valeur,
supprimer:
- estVide est une application de Fil(E) dans (vrai, faux),
estVide(F) est égal à vrai si et seulement si la file F est
vide.
- ajouter est une application de E × Fil(E) dans
Fil(E), ajouter(x,F) est la file obtenue à partir de la file F
en insérant l'élément x à la fin de celle-ci.
- valeur est une application de Fil(E) \ F0 dans
E qui à une file F non vide associe l'élément se trouvant en
tête.
- supprimer est une application de Fil(E)
\ F0 dans Fil(E) qui associe à une file F non vide la
file obtenue à partir de F en supprimant son premier élément.
Les opérations sur les files satisfont les relations suivantes
Pour F ¹ F0
| supprimer(ajouter(x,F)) = ajouter(x ,supprimer(F)) |
| valeur(ajouter(x,F))= valeur(F)
|
Pour toute file F
| estVide(ajouter(x,F)) = faux
|
Pour la file F0
| supprimer(ajouter (x,F0))= F0 |
| valeur(ajouter(x,F0)) = x |
| estVide(F0) = vrai
|
Figure 3.3 : File gérée par un tableau circulaire
Une première idée de réalisation sous forme de programmes des
opérations sur les files est empruntée à une technique mise en
oeuvre dans des lieux où des clients font la queue pour
être servis, il s'agit par exemple de certains guichets de
réservation dans les gares, de bureaux de certaines administrations,
ou des étals de certains supermarchés. Chaque client qui se
présente obtient un numéro et les clients sont ensuite appelés
par les serveurs du guichet en fonction croissante de leur numéro
d'arrivée. Pour gérer ce système deux nombres doivent être
connus par les gestionnaires: le numéro obtenu par le dernier client
arrivé et le numéro du dernier client servi. On note ces deux
nombres par fin et début respectivement et on gère le
système de la façon suivante
- la file d'attente est vide si et seulement si début
= fin,
- lorsqu'un nouveau client arrive on incrémente fin et on
donne ce numéro au client,
- lorsque le serveur est libre et peut servir un autre client, si
la file n'est pas vide, il incrémente début et appelle le
possesseur de ce numéro.
Dans la suite, on a représenté toutes ces opérations en Java en
optimisant la place prise par la file en utilisant la technique
suivante: on réattribue le numéro 0 à un nouveau client lorsque
l'on atteint un certain seuil pour la valeur de fin. On dit
qu'on a un tableau (ou tampon) circulaire.
class File {
final static int MaxF = 100;
int debut;
int fin;
boolean pleine, vide;
int contenu[];
File () {
debut = 0; fin = 0;
pleine = false; vide = true;
contenu = new int[MaxF];
}
static File vide () {
return new File();
}
static void faireVide (File f) {
f.debut = 0; f.fin = 0;
f.pleine = false; f.vide = true;
}
static boolean estVide(File f) {
return f.vide;
}
static boolean estPleine(File f) {
return f.pleine;
}
static int valeur (File f) {
if (f.vide)
erreur ("File Vide.");
return f.contenu[f.debut];
}
private static int Successeur(int i) {
return (i+1) % MaxF;
}
static void ajouter (int x, File f) {
if (f.pleine)
erreur ("File Pleine.");
f.contenu[f.fin] = x;
f.fin = Successeur(f.fin);
f.vide = false;
f.pleine = f.fin == f.debut;
}
static void supprimer (File f) {
if (f.vide)
erreur ("File Vide.");
f.debut = Successeur(f.debut);
f.vide = f.fin == f.debut;
f.pleine = false;
}
}
Une autre façon de gérer des files consiste à utiliser des
listes chaînées gardées (voir page X) dans
lesquelles on connaît à la fois l'adresse du premier et du dernier
élément. Cela donne les opérations suivantes:
class File {
Liste debut;
Liste fin;
File (Liste a, Liste b) {
debut = a;
fin = b;
}
static File vide () {
Liste garde = new Liste();
return new File (garde, garde);
}
static void faireVide (File f) {
Liste garde = new Liste();
f.debut = f.fin = garde;
}
static boolean estVide (File f) {
return f.debut == f.fin;
}
static int valeur (File f) {
Liste b = f.debut.suivant;
return b.contenu;
}
static void ajouter (int x, File f) {
Liste a = new Liste (x, null);
f.fin.suivant = a;
f.fin = a;
}
static void supprimer (File f) {
if (estVide (f))
erreur ("File Vide.");
f.debut = f.debut.suivant;
}
}
Figure 3.4 : File d'attente implémentée par une liste
Nous avons deux réalisations possibles des files avec des tableaux ou
des listes chaînées. L'écriture de programmes consiste à faire de
tels choix pour représenter les structures de données. L'ensemble
des fonctions sur les files peut être indistinctement un module
manipulant des tableaux ou un module manipulant des listes.
L'utilisation des files se fait uniquement à travers les fonctions
vide, ajouter, valeur, supprimer. C'est donc
l'interface des files qui importe dans de plus gros programmes,
et non leurs réalisations. Les notions d'interface et de modules
seront développées au chapitre 7.
3.3 Piles
La notion de pile intervient couramment en programmation, son rôle
principal consiste à implémenter les appels de procédures. Nous
n'entrerons pas dans ce sujet, plutôt technique, dans ce chapitre.
Nous montrerons le fonctionnement d'une pile à l'aide d'exemples
choisis dans l'évaluation d'expressions Lisp.
On peut imaginer une pile comme une boîte dans laquelle on place des
objets et de laquelle on les retire dans un ordre inverse de celui
dans lequel on les a mis: les objets sont les uns sur les autres dans
la boîte et on ne peut accéder qu'à l'objet situé au ``sommet de la
pile''. De façon plus formelle, on se donne un ensemble E,
l'ensemble des piles dont les éléments sont dans E est noté
Pil(E), la pile vide (qui ne contient aucun élément) est P0, les
opérations sur les piles sont vide, ajouter, valeur, supprimer
comme sur les files. Cette fois, les relations satisfaites sont les
suivantes (où P0 dénote la pile vide)
| supprimer(ajouter(x,P)) = P |
| estVide(ajouter(x,P)) = faux |
| valeur(ajouter(x,P)) = x |
| estVide(P0) = vrai
|
A l'aide de ces relations, on peut exprimer toute expression sur les
piles faisant intervenir les 4 opérations précédentes à
l'aide de la seule opération ajouter en partant de la pile P0.
Ainsi l'expression suivante concerne les piles sur l'ensemble des
nombres entiers:
|
| supprimer (ajouter ( | 7 , |
| | | supprimer ( | ajouter ( | valeur (ajouter (5, ajouter (3, P0)))), |
| | | | | ajouter (9, P0))))
|
Elle peut se simplifier en:
La réalisation des opérations sur les piles peut s'effectuer en
utilisant un tableau qui contient les éléments et un indice qui
indiquera la position du sommet de la pile.
par référence.
class Pile {
final static int maxP = 100;
int hauteur ;
Element contenu[];
Pile () {
hauteur = 0;
contenu = new Element[maxP];
}
static File vide () {
return new Pile();
}
static void faireVide (Pile p) {
p.hauteur = 0;
}
static boolean estVide (Pile p) {
return p.hauteur == 0;
}
static boolean estPleine (Pile p) {
return p.hauteur == maxP;
}
static void ajouter (Element x, Pile p)
throws ExceptionPile
{
if (estPleine (p))
throw new ExceptionPile("pleine");
p.contenu[p.hauteur] = x;
++ p.hauteur;
}
static Element valeur (Pile p)
throws ExceptionPile
{
if (estVide (p))
throw new ExceptionPile("vide");
return p.contenu [p.hauteur - 1];
}
static void supprimer (Pile p)
throws ExceptionPile
{
if (estVide (p))
throw new ExceptionPile ("vide");
-- p.hauteur;
}
}
où on suppose qu'une nouvelle classe définit les exceptions
ExceptionPile:
class ExceptionPile extends Exception {
String nom;
public ExceptionPile (String x) {
nom = x;
}
}
Remarques
Chacune des opérations sur les piles demande
un très petit nombre d'opérations élémentaires et ce nombre est
indépendant du nombre d'éléments contenus dans la pile. On peut
gérer aussi une pile avec une liste chaînée, les fonctions
correspondantes sont laissées à titre d'exercice. Les piles ont
été considérées comme des arguments par référence pour éviter
qu'un appel de fonction ne fasse une copie inutile pour passer
l'argument par valeur.
3.4 Evaluation des expressions arithmétiques préfixées
Dans cette section, on illustre l'utilisation des piles par un
programme d'évaluation d'expressions arithmétiques écrites de
façon particulière. Rappelons qu'expression arithmétique
signifie dans le cadre de la programmation: expression faisant
intervenir des nombres, des variables et des opérations
arithmétiques (par exemple: + * / - Ö ). Dans
ce qui suit, pour simplifier, nous nous limiterons aux opérations
binaires + et * et aux nombres naturels. La généralisation à
des opérations binaires supplémentaires comme la division et la
soustraction est particulièrement simple, c'est un peu plus
difficile de considérer aussi des opérations agissant sur un seul
argument comme la racine carrée, cette généralisation est laissée
à titre d'exercice au lecteur. Nous ne considérerons aussi que les
entiers naturels en raison de la confusion qu'il pourrait y avoir
entre le symbole de la soustraction et le signe moins.
Sur certaines machines à calculer de poche, les calculs s'effectuent
en mettant le symbole d'opération après les nombres sur lesquels
on effectue l'opération. On a alors une notation dite postfixée. Dans certains langages de programmation, c'est par
exemple le cas de Lisp ou de Scheme, on écrit les expressions de façon préfixée c'est-à-dire que le symbole d'opération précède
cette fois les deux opérandes, on définit ces expressions
récursivement. Les expressions préfixées comprennent:
- des symboles parmi les 4 suivants:
+ * ( )
- des entiers naturels
Une expression préfixée est ou bien un nombre
entier naturel ou bien est de l'une des deux formes:
(+ e1 e2) (* e1 e2)
où e1 et e2 sont des expressions préfixées.
Cette définition fait intervenir le nom de l'objet que l'on
définit dans sa propre définition mais on peut montrer que cela ne
pose pas de problème logique. En effet, on peut comparer cette
définition à celle des nombres entiers: ``tout entier naturel est
ou bien l'entier 0 ou bien le successeur d'un entier naturel''. On
vérifie facilement que les suites de symboles suivantes sont des
expressions préfixées.
47
(* 2 3)
(+ 12 8)
(+ (* 2 3) (+ 12 8))
(+ (* (+ 35 36) (+ 5 6)) (* (+ 7 8) (* 9 9)))
Leur évaluation donne respectivement 47, 6, 20, 26 et 1996.
Pour représenter une expression préfixée en Java, on utilise ici un
tableau dont chaque élément représente une entité de
l'expression. Ainsi les expressions ci-dessus seront représentées par
des tableaux de tailles respectives 1, 5, 5, 13, 29. Les éléments du
tableau sont des objets à trois champs, le premier indique la nature
de l'entité: (symbole ou nombre), le second champ est rempli par la
valeur de l'entité dans le cas où celle ci est un nombre, enfin le
dernier champ est un caractère rempli dans les cas où l'entité est un
symbole.
class Element {
boolean estOperateur;
int valeur;
char valsymb;
}
On utilise les fonctions données ci-dessus pour les piles et
on y ajoute les procédures suivantes :
static int calculer (char a, int x, int y) {
switch (a) {
case '+': return x + y;
case '*': return x * y;
}
return -1;
}
La procédure d'évaluation consiste à empiler les
résultats intermédiaires, la pile contiendra des opérateurs et
des nombres, mais jamais deux nombres consécutivement. On examine
successivement les entités de l'expression si l'entité est un
opérateur ou si c'est un nombre et que le sommet de la pile est un
opérateur, alors on empile cette entité. En revanche, si c'est un
nombre et qu'en sommet de pile il y a aussi un nombre, on fait agir
l'opérateur qui précède le sommet de pile sur les deux nombres
et on répète l'opération sur le résultat trouvé.
Figure 3.5 : Pile d'évaluation de l'expression dont le résultat est 1996
static void inserer (Element x, Pile p)
throws ExceptionPile
{
Element y, op;
while (!(Pile.estVide(p) || x.estOperateur ||
Pile.valeur(p).estOperateur)) {
y = Pile.valeur(p);
Pile.supprimer(p);
op = Pile.valeur(p);
Pile.supprimer(p);
x.valeur = calculer (op.valsymb, x.valeur, y.valeur);
}
Pile.ajouter(x,p);
}
static int evaluer (Element u[])
throws ExceptionPile
{
Pile p = new Pile();
for (int i = 0; i < u.length ; ++i) {
inserer (u[i], p);
}
return Pile.valeur(p).valeur;
}
Dans ce cas, il peut être utile de donner un exemple de
programme principal pilotant ces diverses fonctions. Remarquer qu'on se
sert des arguments sur la ligne de commande pour séparer les
différents nombres ou opérateurs.
public static void main (String args[]) {
Element exp[] = new Element [args.length];
for (int i = 0; i < args.length; ++i) {
String s = args[i];
if (s.equals ("+") || s.equals ("*"))
exp[i] = new Element (true, 0, s.charAt(0));
else
exp[i] = new Element (false, Integer.parseInt(s), ' ');
}
try {
System.out.println (evaluer (exp));
} catch (ExceptionPile x) {
System.err.println ("Pile " + x.nom);
}
}
3.5 Opérations courantes sur les listes
Nous donnons dans ce paragraphe quelques algorithmes de manipulation
de listes. Ceux-ci sont utilisés dans les langages où la liste
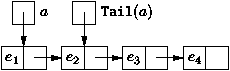
constitue une structure de base. La fonction Tail est une primitive classique, elle supprime le
premier élément d'une liste
Figure 3.6 : Queue d'une liste
class Liste {
Object contenu;
Liste suivant;
Liste (Object x, Liste a) {
contenu = x;
suivant = a;
}
static Liste cons (Object x, Liste a) {
return new Liste (x, a);
}
static Object head (Liste a) {
if (a == null)
erreur ("Head d'une liste vide.");
return a.contenu;
}
static Liste tail (Liste a) {
if (a == null)
erreur ("Tail d'une liste vide.");
return a.suivant;
}
Des procédures sur les listes construisent une liste à partir de
deux autres, il s'agit de mettre
deux listes bout à bout pour en construire une dont la longueur est
égale à la somme des longueurs des deux autres. Dans la première
procédure append, les deux listes ne sont pas modifiées; dans
la seconde nConc, la première liste est transformée pour
donner le résultat. Toutefois, on remarquera que, si append
copie son premier argument, il partage la fin de liste de son
résultat avec son deuxième argument.
Figure 3.7 : Concaténation de deux listes par Append
static Liste append (Liste a, Liste b) {
if (a == null)
return b;
else
return ajouter (a.contenu, append (a.suivant, b)) ;
}
static Liste nConc (Liste a, Liste b) {
if (a == null)
return b;
else {
Liste c = a;
while (c.suivant != null)
c = c.suivant;
c.suivant = b;
return a;
}
}
Cette dernière procédure peut aussi s'écrire récursivement:
static Liste nConc (Liste a, Liste b) {
if (a == null)
return b;
else {
a.suivant = nConc (a.suivant, c);
return a;
}
}
Figure 3.8 : Concaténation de deux listes par Nconc
La procédure de calcul de l'image miroir d'une liste a consiste à
construire une liste dans laquelle les éléments de a sont
rencontrés dans l'ordre inverse de ceux de a. La réalisation de
cette procédure est un exercice classique de la programmation sur les
listes. On en donne ici deux solutions l'une itérative, l'autre
récursive, la complexité est en O(n2) donc quadratique, mais classique. A nouveau, nReverse
modifie son argument, alors que Reverse ne le modifie pas et
construit une nouvelle liste pour son résultat.
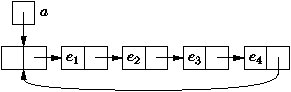
Figure 3.9 : Transformation d'une liste au cours de nReverse
static Liste nReverse (Liste a) {
Liste b = null;
while (a != null) {
Liste c = a.suivant;
a.suivant = b;
b = a;
a = c;
}
return b;
}
static Liste reverse (Liste a) {
if (a == null)
return a;
else
return append (reverse (a.suivant),
ajouter (a.contenu, null));
}
On peut aussi avoir une version linéaire de la version
récursive, grâce à une fonction auxiliaire accumulant le
résultat dans un de ses arguments:
static Liste nReverse (Liste a) {
return nReverse1 (null, a);
}
static Liste nReverse1 (Liste b, Liste a) {
if (a == null)
return b;
else
return nReverse1 (ajouter (a.contenu, b), a.suivant);
}
Un autre exercice formateur consiste à gérer des listes dans
lesquelles les éléments sont rangés en ordre croissant. La procédure
d'ajout devient plus complexe puisqu'on doit retrouver la position de
la cellule où il faut ajouter après avoir parcouru une partie de la
liste.
Nous ne traiterons cet exercice que dans le cas des listes
circulaires gardées, voir page X. Dans une
telle liste, la valeur du champ contenu de la première cellule
n'a aucune importance. On peut y mettre le nombre d'éléments de la
liste si l'on veut. Le champ suivant de la dernière cellule
contient lui l'adresse de la première.
Figure 3.10 : Liste circulaire gardée
static Liste inserer (int v, Liste a) {
Liste b = a;
while (b.suivant != a && v > head(b.suivant))
b = b.suivant;
b.suivant = ajouter (v, b.suivant);
a.contenu = head(a) + 1;
return a;
}
3.6 Programmes en Caml
/* Déclaration des listes, voir page X */
type element == int;;
type liste = Nil | Cons of cellule
and cellule =
{ mutable contenu : element;
mutable suivant : liste };;
Remarque: en Caml, les listes sont prédéfinies, et la majorité des
fonctions suivantes préexistent. Nous nous amusons donc à les
redéfinir. Toutefois, nos nouvelles listes sont modifiables.
(* Liste vide, voir page X *)
let estVide a =
a = Nil;;
(* Ajouter, voir page X *)
let ajouter x a =
Cons {contenu = x; suivant = a};;
(* Recherche, voir page X *)
let recherche x a =
let l = ref a in
let result = ref false in
while !l <> Nil do
match !l with
| Cons {contenu = y; suivant = s} ->
if x = y then result := true
else l := s
| _ -> ()
done;
!result;;
(* Recherche récursive, voir page X *)
let recherche x a =
match a with
Nil -> false
| Cons {contenu = y; suivant = s} ->
if x = y then true
else recherche x s;;
let recherche x a =
match a with
Nil -> false
| Cons {contenu = y; suivant = s} ->
x = y || recherche x s;;
(* Longueur d'une liste, voir page X *)
let rec longueur = function
Nil -> 0
| Cons {suivant = reste; _} ->
1 + longueur reste;;
(* Longueur d'une liste, voir page X *)
let longueur a =
let r = ref 0
and accu = ref a in
while !accu <> Nil do
incr r;
match !l with
| Cons {suivant = reste; _} ->
accu := reste
| _ -> ()
done;
!r;;
(* Supprimer, voir page X *)
let rec supprimer x a =
match a with
Nil -> a
| Cons ({contenu = c; suivant = s} as cellule) ->
if c = x then s
else begin
cellule.suivant <- supprimer x s;
a
end;;
let rec supprimer x a =
match a with
Nil -> Nil
| Cons {contenu = c; suivant = s} ->
if c = x then s
else Cons {contenu = c; suivant = s};;
(* Liste des nombres premiers, voir page X *)
let liste_premier n =
let a = ref Nil in
for i = n downto 2 do ajouter i a done;
let k = ref 2 in
let b = ref !a in
while !k * !k <= n do
match !b with
Nil -> failwith "liste_premier"
| Cons {contenu = c; suivant = s} ->
k := c;
for j = c to n / c do
supprimer (j * !k) a done;
b := s
done;
a;;
(* Les files avec des vecteurs, voir page X *)
let maxF = 100;;
type 'a file =
{ mutable debut: int;
mutable fin: int;
mutable pleine: bool;
mutable vide: bool;
contenu: 'a vect };;
let vide () = {debut = 0; fin = 0;
pleine = false; vide = true;
contenu = make_vect maxF 0};;
let faireVide f = begin
f.debut = 0; f.fin = 0;
f.pleine = false; f.vide = true;
end;;
let estVide f = f.vide;;
let estPleine f = f.pleine;;
let valeur f = begin
if f.vide then failwith "Pile vide.";
f.contenu.(f.debut)
end;;
let successeur x = (x + 1) mod maxF ;;
let ajouter x f = begin
if f.pleine then failwith "Pile pleine.";
f.contenu.(f.fin) <- x;
f.fin <- successeur (f.fin);
f.vide <- false;
f.pleine <- f.fin = f.debut;
end;;
let supprimer f = begin
if f.vide then failwith "File vide.";
f.debut <- successeur (f.debut);
f.vide <- f.fin = f.debut;
f.pleine <- false;
end;;
(* Les files avec des listes, voir page X *)
type 'a liste = Nil | Cons of 'a cellule
and 'a cellule =
{contenu: 'a; mutable suivant: 'a liste};;
type 'a file =
{mutable debut: 'a cellule;
mutable fin: 'a cellule };;
let vide () =
let b = {contenu = 0; suivant = Nil} in
{debut = b; fin = b};;
let faireVide f =
let b = {contenu = 0; suivant = Nil} in
f.debut <- b; f.fin <- b;;
let estVide f = f.fin == f.debut;;
let valeur f =
match f.debut.suivant with
Nil -> failwith "Pile vide"
| Cons cell -> cell.contenu;;
let ajouter x f =
let b = {contenu = x; suivant = Nil} in
f.fin.suivant <- Cons b;
f.fin <- b;;
let supprimer f =
match f.debut.suivant with
Nil -> ()
| Cons cell -> f.debut <- cell;;
(* Déclarations et opérations sur les piles,
voir page X *)
exception ExceptionPile of string;;
let maxP = 100;;
type 'a pile =
{mutable hauteur: int;
mutable contenu: 'a vect};;
let vide () =
{hauteur = 0; contenu = make_vect maxP 0};;
let faireVide p = p.hauteur <- 0;;
let estVide p = p.hauteur = 0;;
let estPleine p = p.hauteur = maxP;;
let ajouter x p =
if estPleine p then
raise (ExceptionPile "pleine");
p.contenu.(p.hauteur) <- x;
p.hauteur <- p.hauteur + 1;;
let pvaleur p =
if estVide p then
raise (ExceptionPile "vide");
p.contenu.(p.hauteur - 1);;
let psupprimer p =
if estVide p then
raise (ExceptionPile "vide");
p.hauteur <- p.hauteur - 1;;
(* Opérations sur les piles, version plus traditionelle *)
type 'a pile == 'a list ref;;
let vide () = ref [];;
let faireVide (p) = p := [];;
let estVide p = (!p = []);;
let ajouter x p = p := x :: !p;;
let valeur p = match !p with
[] -> failwith "Pile Vide."
| x :: p' -> x;;
let supprimer p = p := match !p with
[] -> failwith "Pile Vide."
| x :: p' -> p';;
(* Evaluation des expressions préfixées,
voir page X *)
type expression == element vect
and element =
Symbole of char
| Nombre of int;;
let calculer a x y =
match a with
`+` -> x + y
| `*` -> x * y
| _ -> failwith "unknown operator";;
let rec inserer x p =
match x with
Symbole c -> ajouter x p
| Nombre n ->
if pvide p then ajouter x p else
match valeur p with
Symbole c as y -> ajouter x p
| Nombre m ->
supprimer p;
match valeur p with
Symbole c ->
supprimer p;
let res = Nombre (calculer c n m) in
inserer res p
| _ -> failwith "pile mal construite";;
let evaluer u =
let p =
{hauteur = 0;
contenu = make_vect 100 (Nombre 0)} in
for i = 0 to vect_length u - 1 do
inserer u.(i) p
done;
match valeur p with
Symbole c -> failwith "pile mal construite"
| Nombre n -> n;;
let pile_of_string s =
let u = make_vect (string_length s) (Symbole ` `) in
let l = ref 0 in
for i = 0 to string_length s - 1 do
let element =
match s.[i] with
`0` .. `9` as c ->
let n =
int_of_char c - int_of_char `0` in
begin match u.(!l) with
Symbole c -> Nombre n
| Nombre m ->
decr l; Nombre (10 * m + n)
end
| c -> Symbole c in
incr l;
u.(!l) <- element
done;
sub_vect u 0 !l;;
evaluer
(pile_of_string
"(* (+ 10 (* 2 3)) (+ (* 10 10) (* 9 9)))");;
- : int = 1996
(* Tail et cons, voir page X *)
let tail a =
match a with
Nil -> failwith "tail"
| Cons cell -> cell.contenu;;
let cons x l =
Cons {contenu = x; suivant = l};;
(* Append et nconc, voir page X *)
let rec append a b =
match a with
Nil -> b
| Cons cell ->
cons (cell.contenu)
(append cell.suivant b);;
let nconc ap b =
match !ap with
Nil -> ap := b
| _ ->
let c = ref !ap in
while
match !c with
Cons {suivant = (Cons cell as l); _} ->
c := l; true
| _ -> false
do () done;
match !c with
Cons cell -> cell.suivant <- b
| _ -> ();;
(* Version plus conforme au style Caml:
avec une fonction récursive locale,
on fait l'opération physique sur la liste *)
let rec nconc a b =
let rec nconc1 c =
match c with
Nil -> b
| Cons ({suivant = Nil; _} as cell) ->
cell.suivant <- b; a
| Cons {suivant = l; _} -> nconc1 l in
nconc_aux a;;
(* Nreverse et reverse,
voir page X *)
let nreverse ap =
let a = ref !ap in
let b = ref Nil in
let c = ref Nil in
while
match !a with
| Nil -> false
| Cons ({suivant = s; _} as cell) ->
c := s;
cell.suivant <- !b;
b := !a;
a := !c;
true
do () done;
ap := !b;;
(* Version plus conforme à Caml:
on renverse la liste en place
et l'on rend la nouvelle tête de liste *)
let nreverse l =
let rec nreverse1 a b =
match a with
| Nil -> b
| Cons ({suivant = s; _} as cell) ->
cell.suivant <- b;
nreverse1 s a in
nreverse_aux l Nil;;
let rec reverse a =
match a with
| Nil -> a
| Cons cell ->
append (reverse cell.suivant)
(cons (cell.contenu) Nil);;
(* Insert, voir page X *)
let insert v l =
match l with
Nil -> failwith "insert"
| Cons c ->
let rec insert_aux a =
match a with
| Nil -> failwith "insert"
| Cons cell ->
if v > cell.contenu && cell != c
then insert_aux cell.suivant
else cell.suivant <-
cons v cell.suivant in
insert_aux c.suivant;
c.contenu <- l.contenu + 1;;