Annexe A Java
Le langage Java a été conçu par Gosling et ses collčgues ŕ Sun
microsystems comme une simplification du C++ de Stroustrup [49].
Le langage, prévu initialement pour programmer de petits automatismes,
s'est vite retrouvé comme le langage de programmation du World Wide
Web, car son interpréteur a été intégré dans pratiquement tous les
navigateurs existants. Il se distingue de C++ par son typage fort (il n'y
pas par exemple de possibilité de changer le type d'une donnée sans
vérifications) et par son systčme de récupération automatique de la
mémoire (glaneur de cellules ou GC ou garbage collector en
anglais). Trčs rapidement, le langage est devenu trčs populaire,
quoiqu'ayant besoin d'une technologie de compilation plus avancée que
C++. De multiples livres le décrivent, et il est un peu vain de
vouloir les résumer ici. Parmi ces livres, les plus intéressants nous
semblent dans l'ordre
[j1,j2,j3,j4].
Comme C++, Java fait partie des langages orientés-objets, dont les
ancętres sont le Simula-67 de Dhal et Nygaard et Smalltalk de Deutsch,
Kay, Goldberg et Ingalls [13], auquel il faut adjoindre
les nombreuses extensions objets de langages préexistants comme Mesa,
Cedar, Modula-3, Common Lisp, Caml. Cette technique de programmation
peu utilisée dans notre cours (mais enseignée en cours de majeure) a
de nombreux fans, et est męme devenu un argument commercial pour la
diffusion d'un langage de programmation.
A.1 Un exemple simple
Considérons l'exemple des carrés magiques. Un carré magique est une
matrice a carrée de dimension n × n telle que la somme des
lignes, des colonnes, et des deux diagonales soient les męmes. Si n
est impair, on met 1 au milieu de la derničre ligne en an, ë
n/2 ű + 1. On suit la premičre diagonale (modulo n) en
mettant 2, 3, .... Dčs qu'on rencontre un élément déjŕ vu, on monte
d'une ligne dans la matrice, et on recommence. Ainsi voici des carrés
magiques d'ordre 3, 5, 7
|
| |
ć
ç
ç
ç
ç
č
|
| 11 | 18 | 25 | 2 | 9 |
| 10 | 12 | 19 | 21 | 3 |
| 4 | 6 | 13 | 20 | 22 |
| 23 | 5 | 7 | 14 | 16 |
| 17 | 24 | 1 | 8 | 15
| | |
ö
÷
÷
÷
÷
ř
| | |
ć
ç
ç
ç
ç
ç
ç
ç
č
|
| 22 | 31 | 40 | 49 | 2 | 11 | 20 |
| 21 | 23 | 32 | 41 | 43 | 3 | 12 |
| 13 | 15 | 24 | 33 | 42 | 44 | 4 |
| 5 | 14 | 16 | 25 | 34 | 36 | 45 |
| 46 | 6 | 8 | 17 | 26 | 35 | 37 |
| 38 | 47 | 7 | 9 | 18 | 27 | 29 |
| 30 | 39 | 48 | 1 | 10 | 19 | 28
| | |
ö
÷
÷
÷
÷
÷
÷
÷
ř
| | | |
Exercices
1- Montrer que les sommes sont bien
les męmes, 2- Peut-on en construire d'ordre pair?
import java.io.*;
import java.lang.*;
import java.util.*;
class CarreMagique {
final static int N = 100;
static int a[][] = new int[N][N];
static int n;
static void init (int n){
for (int i = 0 ; i < n; ++i)
for (int j = 0; j < n; ++j)
a[i][j] = 0;
}
static void magique (int n) {
int i, j;
i = n - 1; j = n / 2;
for (int k = 1; k <= n * n; ++k) {
a[i][j] = k;
if ((k % n) == 0)
i = i - 1;
else {
i = (i + 1) % n;
j = (j + 1) % n;
}
}
}
static void erreur (String s) {
System.err.println ("Erreur fatale: " + s);
System.exit (1);
}
static int lire () {
int n;
BufferedReader in =
new BufferedReader(new InputStreamReader(System.in));
System.out.print ("Taille du carré magique, svp?:: ");
try {
n = Integer.parseInt (in.readLine());
}
catch (IOException e) {
n = 0;
}
catch (ParseException e) {
n = 0;
}
if ((n <= 0) || (n > N) || (n % 2 == 0))
erreur ("Taille impossible.");
return n;
}
static void imprimer (int n) {
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j)
System.out.print (leftAligned(5, a[i][j] + " "));
System.out.println ();
}
}
static String leftAligned (int size, String s) {
StringBuffer t = new StringBuffer (s);
for (int i = s.length(); i < size; ++i)
t = t.append(" ");
return new String (t);
}
public static void main (String args[]) {
n = lire();
init(n); // inutile, mais pédagogique!
magique(n);
imprimer(n);
}
}
D'abord, on remarque qu'un programme est une suite de directives et de
déclarations de classes. Ici, nous n'avons qu'un seule classe
CarreMagique. Auparavant nous avons quelques directives sur un
nombre de classes standard dont nous allons nous servir sans utiliser
la notation longue (cf plus loin). Chaque classe contient un certain
nombre de déclarations de variables et de fonctions ou procédures. (En
programmation objet, on parle de méthodes au lieu de fonctions
ou de procédures. Ici nous utiliserons les deux terminologies). Une
des fonctions, conventionnellement de nom main, est le point de
départ du programme. Ignorons ses arguments pour le moment.
Dans notre exemple, la fonction main lit l'entier n ŕ la
console, initialise la matrice a avec des zéros, puis calcule un
carré magique d'ordre n et l'imprime. Nous regardons maintenant les
autres fonctions et procédures. Remarquons que les commentaires sont
compris entre les séparateurs /* et */, ou aprčs
// comme en C++.
La classe CarreMagique commence par la déclaration de trois
variables. La premičre déclaration définit une constante N
entičre (integer en anglais, int en abrégé) qui
représente la taille maximale du carré autorisé. Il est fréquent
d'écrire les constantes avec des majuscules uniquement. Nous adoptons
la convention suivante sur les noms: les noms de constantes ou de
classes commencent par des majuscules, les noms de variables ou de
fonctions commencent par une minuscule. On peut ne pas respecter cette
convention, mais cela rendra les programmes moins lisibles. (Pour le
moment, nous n'essayons pas de comprendre les mots clés
final ou static --- ce deuxičme mot-clé reviendra trčs
souvent dans nos programmes).
Aprčs N, on déclare un tableau a d'entiers ŕ deux
dimensions (la partie écrite avant le symbole =) et on alloue
un tableau N × N d'entiers qui sera sa valeur. Cette
déclaration peut sembler trčs compliquée, mais les tableaux adoptent
la syntaxe des objets (que nous verrons plus tard) et cela permettra
d'initialiser les tableaux par d'autres expressions. Remarquons que
les bornes du tableau ne font pas partie de la déclaration. Enfin, une
troisičme déclaration dit qu'on se servira d'une variable entičre
n, qui représentera l'ordre du carré magique ŕ calculer.
Ensuite, dans la classe CarreMagique, nous n'avons plus que des
définitions de fonctions. Considérons la premičre init, pas
vraiment utile, mais intéressante puisque trčs simple. Le type
void de son résultat est vide, il est indiqué avant la
déclaration de son nom, comme pour les variables ou les tableaux. (En
Pascal, on parlerait de procédure). Elle a un seul paramčtre entier
n (donc différent de la variable globale définie auparavant).
Cette procédure remet ŕ zéro toute la matrice a. Remarquons qu'on
écrit a[i][j] pour son élément ai,j (0 Ł i,j < n), et
que le symbole d'affectation est = comme en C ou en Fortran
(l'opérateur = pour le test d'égalité s'écrit ==). Les
tableaux commencent toujours ŕ l'indice 0. Deux boucles imbriquées
permettent de parcourir la matrice. L'instruction for a trois
clauses: l'initialisation, le test pour continuer ŕ itérer et
l'incrémentation ŕ chaque itération. On initialise la variable fraiche
i ŕ 0, on continue tant que i < n, et on incrémente i de 1 ŕ
chaque itération (++ et -- sont les symboles
d'incrémentation et de décrémentation).
Considérons la fonction imprimer. Elle a la męme structure,
sauf que nous imprimons chaque élément sur 5 caractčres cadrés ŕ
gauche. Les deux fonctions de librairie System.out.print et
System.out.println permettent d'écrire leur paramčtre (avec un
retour ŕ la ligne dans le cas de la deuxičme). Le paramčtre est
quelconque et peut męme ne pas exister, c'est le cas ici pour
println. Il est trop tôt pour expliquer le détail de
leftAligned, introduit ici pour rendre l'impression plus jolie,
et supposons que l'impression est simplement déclenchée par
System.out.print (a[i][j] + " ");
Alors, que veut-dire a[i][j] + " " ?? A gauche de l'opérateur
+, nous avons l'entier ai,j et ŕ droite une chaîne de
caractčres!! Il ne s'agit bien sűr pas de l'addition sur les entiers,
mais de la concaténation des chaînes de caractčres. Donc +
transforme son argument de gauche dans la chaîne de caractčres qui le
représente et ajoute au bout la chaîne " " contenant un espace
blanc. La procédure devient plus claire. On imprime tous les éléments
ai,j séparés par un espace blanc avec un retour ŕ la ligne en fin
de ligne du tableau. La fonction compliquée leftAligned ne fait
que justifier sur 5 caractčres cette impression (il n'existe pas
d'impression formattée en Java). En conclusion, on constate que
l'opérateur + est surchargé, car il a deux sens en Java:
l'addition arithmétique, mais aussi la concaténation des chaînes de
caractčres dčs qu'un de ses arguments est une chaîne de
caractčres. C'est le seul opérateur surchargé (contrairement ŕ C++ qui
autorise tous ses opérateurs ŕ ętre surchargés).
La procédure erreur prend comme argument la chaîne de
caractčres s et l'imprime précédée d'un message insistant sur
le coté fatal de l'erreur. Ici encore, on voit l'utilisation de
+ pour la concaténation de deux chaînes de caractčres. Puis, la
procédure fait un appel ŕ la fonction systčme exit
qui arręte l'exécution du programme avec un code
d'erreur (0 voulant dire arręt normal, tout autre valeur un arręt
anormal). (Plus tard, nous verrons qu'il y a bien d'autres maničres de
générer un message d'erreur, avec les exceptions ou les erreurs
pré-définies).
La fonction lire qui n'a pas d'arguments retourne un entier lu
ŕ la console. La fonction commence par la déclaration d'une variable
entičre n qui contiendra le résultat retourné. Puis, une ligne
cryptique (ŕ apprendre par coeur) permet de dire que l'on va faire une
lecture (avec tampon) ŕ la console. On imprime un message (sans retour
ŕ la ligne) demandant de rentrer la taille voulue pour le carré
magique, et on lit par readLine une chaîne de caractčre entrée
ŕ la console. Cette chaîne est convertie en entier par la fonction
parseInt et le tout est rangé dans la variable n. Si une
erreur se produit au cours de la lecture, on récupčre cette erreur et
on positionne n ŕ zéro. L'instruction try permet de
délimiter un ensemble d'instruction oů on pourra récupérer une
exception par un catch qui spécifie les exceptions attendues et
l'action ŕ tenir compte en conséquence. Tous les langages modernes ont
un systčme d'exceptions, qui permet de séparer le traitement des
erreurs du traitement normal d'un groupe d'instructions. Notre
fonction lire finit par tester si 0 Ł n < N et si n est
impair (c'est ŕ dire n mod 2 ą 0). Enfin, la fonction retourne de
son résultat.
Il ne reste plus qu'ŕ considérer le coeur de notre problčme, la
construction d'un carré magique d'ordre n impair. On remarquera que
la procédure est bien courte, et que l'essentiel de notre programme
traite des entrées-sortie. C'est un phénomčne général en informatique:
l'algorithme est ŕ un endroit trčs localisé, mais trčs critique, d'un
ensemble bien plus vaste. On a vu que pour construire le carré, on
démarre sur l'élément an, ë n/2 ű + 1. On y met la
valeur 1. On suit une parallčle ŕ la premičre diagonale (modulo n),
en déposant 2, 3, ..., n. Quand l'élément suivant de la matrice
est non vide, on revient en arričre et on recommence sur la ligne
précédente, jusqu'ŕ remplir tout le tableau. Comme on sait exactement
quand on rencontre un élément non vide, c'est ŕ dire quand la valeur
rangée dans la matrice est un multiple de n, la procédure devient
remarquablement simple. (Remarque syntaxique: le point-virgule avant
le else ferait hurler tout compilateur Pascal. En Java comme en
C, le point-virgule fait partie de l'instruction. Simplement toute
expression suivie de
point-virgule devient une instruction. Pour composer plusieurs
instructions en séquence, on les concatčne entre des accolades comme
dans la deuxičme alternative du if ou dans l'instruction
for).
Remarquons que le programme serait plus simple si au lieu de lire n
sur la console, on le prenait en arguments de main. En effet,
l'argument de main est un tableau de chaînes de caractčres, qui
sont les différents arguments pour lancer le programme Java sur la
ligne de commande. Alors on supprimerait lire et main
deviendrait:
public static void main (String args[]) {
if (args.length < 1)
erreur ("Il faut au moins un argument.");
n = Integer.parseInt(args[0]);
init(n); // inutile, mais pédagogique!
magique(n);
imprimer(n);
}
A.2 Quelques éléments de Java
A.2.1 Symboles, séparateurs, identificateurs
Les identificateurs sont des séquences de lettres et de chiffres commençant
par une lettre. Les identificateurs sont séparés par des espaces, des
caractčres de tabulation, des retours ŕ la ligne ou par des caractčres
spéciaux comme +, -, *. Certains identificateurs ne
peuvent ętre utilisés pour des noms de variables ou procédures, et sont
réservés pour des mots clés de la syntaxe, comme class,
int, char, for, while, ....
A.2.2 Types primitifs
Les entiers ont le type byte, short, int ou
long, selon qu'on représente ces entiers signés sur 8, 16, 32 ou 64
bits. On utilise principalement int, car toutes les machines ont des
processeurs 32 bits, et bientôt 64 bits. Attention: il y a 2 conventions
bien spécifiques sur les nombres entiers: les nombres commençant par
0x sont des nombres hexadécimaux. Ainsi 0xff vaut 255. De
męme, sur une machine 32 bits, 0xffffffff vaut -1. Les constantes
entičres longues sont de la forme 1L, -2L. Les plus petites et
plus grandes valeurs des entiers sont Integer.MIN_VALUE = -231,
Integer.MAX_VALUE = 231 -1, des entiers longs
Long.MIN_VALUE = -263, Long.MAX_VALUE = 263 -1,
Byte.MIN_VALUE = -128, Byte.MAX_VALUE = 127, etc.
Les réels ont le type float ou double. Ce sont des nombres
flottants en simple ou double précision. Les constantes sont en notation
décimale 3.1416 ou en notation avec exposant 31.416e-1 et
respectent la norme IEEE 754. Par défaut les constantes sont prise en double
précision, 3.1416f est un flottant en simple précision. Les valeurs
minimales et maximales sont Float.MIN_VALUE et
Float.MAX_VALUE. Il existe aussi les constantes de la norme IEEE,
Float.POSITIVE_INFINITY, Float.NEGATIVE_INFINITY,
Float.NaN, etc.
Les booléens ont le type boolean. Les constantes booléennes sont
true et false.
Les caractčres sont de type char. Les constantes sont écrites entre
apostrophes, comme 'A', 'B', 'a', 'b',
'0', '1', ' '. Le caractčre apostrophe se note
'\'', et plus généralement il y a des conventions pour des caractčres
fréquents, '\n' pour newline, '\r' pour retour-charriot,
'\t' pour tabulation, '\\' pour \. Attention: les
caractčres sont codés sur 16 bits, avec le standard international Unicode.
On peut aussi écrire un caractčre par son code '\u0' pour le
caractčre nul (code 0).
Les constantes chaînes de caractčres sont écrites entre guillemets, comme
dans "Pierre et Paul". On peut mettre des caractčres spéciaux ŕ
l'intérieur, par exemple "Pierre\net\nPaul\n" qui s'imprimera sur
trois lignes. Pour mettre un guillemet dans une chaîne, on écrit
\". Si les constantes de type chaînes de caractčres ont une syntaxe
spéciale, la classe String des chânes de caractčres n'est pas un
type primitif.
En Java, il n'y a pas de type énuméré. On utilera des constantes normales
pour représenter de tels types. Par exemple:
final static int BLEU = 0, BLANC = 1, ROUGE = 2;
int c = BLANC;
A.2.3 Expressions
Expressions élémentaires
Les expressions arithmétiques s'écrivent comme en mathématiques. Les
opérateurs arithmétiques sont +, -, *, /, et
% pour modulo. Les opérateurs logiques sont >, >=,
<, <=, == et != pour faire des comparaisons (le
dernier signifiant ą). Plus intéressant, les opérateurs && et
|| permettent d'évaluer de la gauche vers la droite un certain nombre
de conditions (en fait toutes les expressions
s'évaluent de la gauche vers la droite ŕ la différence de C ou de Caml dont
l'ordre peut ętre laissé ŕ la disposition de l'optimiseur). Une expression
logique (encore appelée booléenne) peut valoir true ou
false. La négation est représentée par l'opérateur !. Ainsi
(i < N) && (a[i] != '\n') && !exception
donnera la valeur true si i <
N et si a[i] ą newline et si
exception = false. Son résultat sera false dčs
que i ł N sans tester les autres prédicats
de cette conjonction, ou alors si i < N et
a[i] = newline, ....
Conversions
Il est important de bien comprendre les rčgles de conversions implicites
dans l'évaluation des expressions. Par exemple, si f est réel, et si
i est entier, l'expression f + i est un réel qui s'obtient par
la conversion implicite de i vers un float. Certaines
conversions sont interdites, comme par exemple indicer un tableau par un
nombre réel. En général, on essaie de faire la plus petite conversion
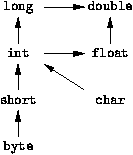
permettant de faire l'opération (cf. figure
A.1). Ainsi un caractčre n'est qu'un petit entier.
Ce qui permet de faire facilement certaines fonctions comme la fonction qui
convertit une chaîne de caractčres ASCII en un entier (atoi est un
raccourci pour Ascii To Integer)
static int atoi (String s)
{
int n = 0;
for (int i = 0; i < s.length(); ++i)
n = 10 * n + (s.charAt(i) - '0');
return n;
}
On peut donc remarquer que s.charAt(i) - '0' permet de
calculer l'entier qui représente la différence entre le code de
s.charAt(i) et celui de '0'. N'oublions pas que cette fonction
est plus simplement calculée par Integer.parseInt(s).
Figure A.1 : Conversions implicites
Les conversions implicites suivent la figure
A.1. Pour toute opération, on convertit toujours au
le plus petit commun majorant des types des opérandes. Des conversions
explicites sont aussi possibles, et recommandées dans le doute. On peut les
faire par l'opération de coercion (cast) suivante
(type-name) expression
L'expression est alors convertie dans le type indiqué entre
parenthčses devant l'expression. L'opérateur = d'affectation est un
opérateur comme les autres dans les expressions. Il subit donc les męmes
lois de conversion. Toutefois, il se distingue des autres opérations par le
type du résultat. Pour un opérateur ordinaire, le type du résultat est le
type commun obtenu par conversion des deux opérandes. Pour une affectation,
le type du résultat est le type de l'expression ŕ gauche de
l'affectation. Il faut donc faire une conversion explicite sur l'expression
de droite pour que le résultat soit cohérent avec le type de l'expression de
gauche. Enfin, dans les appels de fonctions, il y a aussi une opération
similaire ŕ une affectation pour passer les arguments, et donc des
conversions des arguments sont possibles.
Affectation
Quelques opérateurs sont moins classiques: l'affectation,
les opérations d'incrémentation et les opérations sur les bits. L'affectation est un opérateur qui rend comme valeur la
valeur affectée ŕ la partie gauche. On peut donc écrire simplement
x = y = z = 1;
pour
x = 1; y = 1; z = 1;
Une expression qui contient une affectation modifie donc la valeur
d'une variable pendant son évaluation. On dit alors que cette
expression a un effet de bord
.
Les effets de bord sont ŕ manipuler avec précautions, car leur effet peut
dépendre d'un ordre d'évaluation trčs complexe. Il est par exemple peu
recommandé de mettre plus qu'un effet de bord dans une expression.
Expressions d'incrémentation
D'autres opérations dans les expressions peuvent changer la valeur
des variables. Les opérations de pré-incrémentation, de
post-incrémentation, de pré-décrémentation, de
post-décrémentation permettent de donner la valeur d'une variable en
l'incrémentant ou la décrémentant avant ou aprčs de lui ajouter ou
retrancher 1. Supposons que n vaille 5, alors le programme
suivant
x = ++n;
y = n++;
z = --n;
t = n--;
fait passer n ŕ 6, met 6 dans x, met 6 dans
y, fait passer n ŕ 7, puis retranche 1 ŕ n pour
lui donner la valeur 6 ŕ nouveau, met cette valeur 6 dans z et
dans t, et fait passer n ŕ 5. Plus simplement, on peut
écrire simplement
++i;
j++;
pour
i = i + 1;
j = j + 1;
De maničre identique, on pourra écrire
if (c != ' ')
c = s.charAt.(i++);
pour
if (c != ' ') {
c = s.charAt.(i);
++i;
}
En rčgle générale, il ne faut pas abuser des opérations
d'incrémentation. Si c'est une commodité d'écriture comme dans les
deux cas précédents, il n'y a pas de problčme. Si l'expression
devient incompréhensible et peut avoir plusieurs résultats possibles
selon un ordre d'évaluation dépendant de l'implémentation, alors il
ne faut pas utiliser ces opérations et on doit casser l'expression en
plusieurs morceaux pour séparer la partie effet de bord.
| On ne doit pas faire trop d'effets de bord dans une
męme expression |
Expressions sur les bits
Les opérations sur les bits peuvent se révéler, elles, trčs
utiles. On peut faire & (et logique), | (ou
logique), ^ (ou exclusif), << (décalage vers la
gauche), >> (décalage vers la droite), ~ (complément ŕ
un). Ainsi
x = x & 0xff;
y = y | 0x40;
mettent dans x les 8 derniers bits de x et
positionne le 6čme bit ŕ partir de la droite
dans y. Il faut bien distinguer les opérations logiques
&& et || ŕ résultat booléens 0 ou 1 des opérations
& et | sur les bits qui donnent toute valeur
entičre. Par exemple, si x vaut 1 et y vaut 2, x
& y vaut 0 et x && y vaut 1.
Les opérations << et >> décalent leur opérande de
gauche de la valeur indiquée par l'opérande de droite. Ainsi 3
<< 2 vaut 12, et 7 >> 2 vaut 1. Les décalages ŕ gauche
introduisent toujours des zéros sur les bits de droite. Pour les bits
de gauche dans le cas des décalages ŕ droite, c'est dépendant de
la machine; mais si l'expression décalée est unsigned, ce
sont toujours des zéros.
Le complément ŕ un est trčs utile dans les expressions sur les bits. Il permet d'écrire des expressions indépendantes de la
machine. Par exemple
x = x & ~0x7f;
remet ŕ zéro les 7 bits de gauche de x,
indépendamment du nombre de bits pour représenter un entier. Une
notation, supposant des entiers sur 32 bits et donc dépendante de la
machine, serait
x = x & 0xffff8000;
Autres expressions d'affectation
A titre anecdotique, les opérateurs d'affectation peuvent ętre plus
complexes que la simple affectation et permettent des abréviations
parfois utiles. Ainsi, si op est un des opérateurs +,
-, *, /, %, <<, >>,
&, ^, ou |,
e1 op= e2
est un raccourci pour
e1 = e1 op e2
Expressions conditionnelles
Parfois, on peut trouver un peu long d'écrire
if (a > b)
z = a;
else
z = b;
L'expression conditionnelle
e1 ? e2 : e3
évalue e1 d'abord. Si non nul, le résultat est e2,
sinon e3. Donc le maximum de a et b peut s'écrire
z = (a > b) ? a : b;
Les expressions conditionnelles sont des expressions comme
les autres et vérifient les lois de conversion. Ainsi si e2 est
flottant et e3 est entier, le résultat sera toujours flottant.
Précédence et ordre d'évaluation
Certains opérateurs ont des précédences évidentes, et limitent
l'utilisation des parenthčses dans les expressions. D'autres sont
moins clairs, particuličrement en C oů leur nombre est plus grand
qu'en Pascal. Voici la table donnant les précédences dans l'ordre
décroissant et le parenthésage en cas d'égalité
| Opérateurs | Associativité |
() [] -> . | | | gauche ŕ droite |
! ~ ++ -- + - = * & (type) sizeof | | | droite ŕ gauche |
* / % | | | gauche ŕ droite |
+ - | | | gauche ŕ droite |
<< >> | | | gauche ŕ droite |
< <= > >= | | | gauche ŕ droite |
== != | | | gauche ŕ droite |
& | | | gauche ŕ droite |
^ | | | gauche ŕ droite |
| | | | gauche ŕ droite |
&& | | | gauche ŕ droite |
|| | | | gauche ŕ droite |
?: | | | droite ŕ gauche |
= += -= /= %= &= ^= |= <<= >>= | | | droite ŕ gauche |
, | | | gauche ŕ droite |
| | |
En rčgle générale, il est conseillé de mettre des
parenthčses si les précédences ne sont pas claires. Par exemple
if ((x & MASK) == 0) ...
A.2.4 Instructions
Toute expression suivie d'un point-virgule devient une
instruction. Ainsi
x = 3;
++i;
System.out.print(...);
sont des instructions (une expression d'affectation,
d'incrémentation, un appel de fonction suivi de point-virgule). Donc
point-virgule fait partie de l'instruction, et n'est pas un
séparateur comme en Pascal. De męme, les accolades { }
permettent de regrouper des instructions en séquence. Ce qui permet
de mettre plusieurs instructions dans les alternatives d'un if
par exemple.
Les instructions de contrôle sont ŕ peu prčs les męmes qu'en
Pascal. D'abord les instructions conditionnelles if sont de la
forme
if (E)
S1
ou
if (E)
S1
else
S2
Remarquons bien qu'une instruction peut ętre une
expression suivie d'un point-virgule (contrairement ŕ Pascal). Donc
l'instruction suivante est complčtement licite
if (x < 10)
c = '0' + x;
else
c = 'a' + x - 10;
Il y a la męme convention qu'en Pascal pour les if
emboîtés. Le else se rapportant toujours au if le plus
proche. Une série de if peut ętre remplacée par une
instruction de sélection par cas, c'est l'instruction switch.
Elle a la syntaxe suivante
switch (E) {
case c1: instructions
case c2: instructions
...
case cn: instructions
default: instructions
}
Cette instruction a une idiosyncrasie bien particuličre.
Pour sortir de l'instruction, il faut exécuter une instruction
break. Sinon, le reste de l'instruction est fait en séquence.
Cela permet de regrouper plusieurs alternatives, mais peut ętre
particuličrement dangereux. Par exemple, le programme suivant
switch (c) {
case '\t':
case ' ':
++ nEspaces;
break;
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
++ nChiffres;
break;
default:
++ nAutres;
break;
}
permet de factoriser le traitement de quelques cas. On verra
que l'instruction break permet aussi de sortir des boucles. Il
faudra donc bien faire attention ŕ ne pas oublier le break ŕ
la fin de chaque cas, et ŕ ce que break ne soit pas
intercepté par une autre instruction.
Les itérations sont réalisées par les instructions for, while,
et do...while. L'instruction while permet d'itérer tant qu'une
expression booléenne est vraie, on itčre l'instruction S tant que la
condition E est vraie par
while (E)
S
et on fait de męme en effectuant au moins une fois la
boucle par
do
S
while (E);
L'instruction d'itération la plus puissante est l'instruction
for. Sa syntaxe est
for (E1; E2; E3)
S
qui est équivalente ŕ
E1;
while (E2) {
S;
E3;
}
Elle est donc beaucoup plus complexe qu'en Pascal ou Caml et peut
donc ne pas terminer, puisque les expressions E2 et E3 sont
quelconques. On peut toujours écrire des itérations simples:
for (i = 0; i < 100; ++i)
a[i] = 0;
mais l'itération suivante est plus complexe (voir page
X)
for (int i = h(x); i != -1; i = col[i])
if (x.equals(nom[i]))
return tel[i];
Nous avons vu que l'instruction break permet de sortir d'une
instruction switch, mais aussi de toute instruction
d'itération. De męme, l'instruction continue permet de passer
brusquement ŕ l'itération suivante. Ainsi
for (i = 0; i < n; ++i) {
if (a[i] < 0)
continue;
...
}
C'est bien commode quand le cas ai ł 0 est trčs long. Les
break et continue peuvent préciser l'étiquette de l'itération
qu'elles référencent. Ainsi, dans l'exemple suivant, on déclare une
étiquette devant l'instruction while, et on sort des deux itérations
comme suit:
boucle:
while (E) {
for (i = 0; i < n; ++i) {
if (a[i] < 0)
break boucle;
...
}
}
Finalement, il n'y a pas d'instruction goto. Il y a toutefois des
exceptions que nous verrons plus tard.
A.2.5 Procédures et fonctions
La syntaxe des fonctions et procédures a déjŕ été vue dans l'exemple
du carré magique. Chaque classe contient une suite linéaire de
fonctions ou procédures, non emboîtées. Par convention, le début de
l'exécution est donné ŕ la procédure publique main qui prend un
tableau de chaînes de caractčres comme argument. Pour déclarer une
fonction, on déclare d'abord sa signature, c'est ŕ dire le type de son
résultat et des arguments, puis son corps, c'est ŕ dire la suite
d'instructions qui la réalisent entre accolades. Ainsi dans
static int suivant (int x) {
if (x % 2 == 1)
return 3 * x + 1;
else
return x / 2;
}
le résultat est de type entier (ŕ cause du mot-clé int avant
suivant) et l'unique argument x est aussi entier.
L'instruction
return e;
sort de la fonction en donnant le résultat e, et permet de
rendre un résultat ŕ la fonction. Dans les deux fonctions qui suivent, le
résultat est vide, donc de type void et l'argument est entier.
static void test (int x) {
while (x != 1)
x = suivant (x);
}
static void testConjecture (int n) {
for (int x=1; x <= n; ++x) {
test (x);
System.out.println (x);
}
}
On calcule donc les itérations de la fonction qui renvoie 3x+1 si x est
impair, et ë x/2 ű sinon. (En fait, on ne sait pas démontrer
qu'on finit toujours avec 1 pour tout entier x de départ. Par exemple, ŕ
partir de 7, on obtient 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4,
2, 1).
Il peut y avoir des variables locales dans une procédure, plus exactement
dans toute instruction composée entourée par des accolades. Les variables
globales sont elles déclarées au męme niveau que les procédures ou
fonctions. Les variables locales peuvent ętre initialisées. Cela revient ŕ
faire la déclaration et l'affectation par la valeur initiale, qui peut ętre
une expression complexe et qui est évaluée ŕ chaque entrée dans la fonction.
Les variables locales disparaissent donc quand on quitte la fonction.
Dans une fonction, on peut accéder aux variables globales et éventuellement
les modifier, quoiqu'il est recommandé de ne pas faire trop d'effets de
bord, mais on ne pourra passer une variable en argument pour modifier sa
valeur. Prenons l'exemple de la fonction suivant précédente, on a
changé la valeur du paramčtre x dans le corps de la fonction. Mais ceci
n'est vrai qu'ŕ l'intérieur du corps de la fonction. En Java, seule la
valeur du paramčtre compte, on ne modifiera donc pas ainsi une variable
extérieure ŕ la fonction, passée en paramčtre.
| Les paramčtres des fonctions sont passés par valeur |
A.2.6 Classes
Une classe est ŕ la fois la déclaration d'un type non primitif et
d'une série de fonctions ou procédures associés. L'idée est de
découper en petits modules l'espace des données et des fonctions. Les
éléments de l'ensemble représenté par une classe sont les objets. Dans
une classe, il y a une partie champs de données, et une autre qui est
un ensemble de fonctions ou procédures. Dans la programmation
orientée-objet, on aime parler d'objets comme des intances d'une
classe, et de méthodes pour les fonctions et procédures associées
(``méthodes'' car ce sont souvent des méthodes d'accčs aux objets de
la classe que réalisent ces fonctions). Bien sűr, il peut y avoir des
classes sans données ou sans méthodes. Prenons le cas d'une structure
d'enregistrement classique en Pascal ou en C. On peut écrire:
class Date {
int j; /* Jour */
int m; /* Mois */
int a; /* Année */
};
et par la suite on peut déclarer des variables, comme on le
faisait avec les variables de type primitif (entier, réel, caractčre ou
booléen). Ainsi on note deux dates importantes
static final int Jan=1, Fev=2, Mar=3, Avr=4, Mai=5, Juin=6,
Juil=7, Aou=8, Sep=9, Oct=10, Nov=11, Dec=12;
Date bastille = new Date(), berlin = new Date();
bastille.j = 14; bastille.m = Juil; bastille.a = 1789;
berlin.j = 10; berlin.m = Nov; berlin.a = 1989;
Nous venons de définir deux objets bastille et
berlin, et pour accéder ŕ leurs champs on utilise la notation bien
connue suffixe avec un point. Le champ jour de la date de la prise de la
Bastille s'obtient donc par bastille.j. Rien de neuf, c'est la
notation utilisée en Pascal, en C, ou en Caml. Pour créer un objet, on
utilise le mot-clé new suivi du nom de la classe et de parenthčses.
(Pour les experts, les objets sont représentés par un pointeur et leur
contenu se trouve dans le tas). Un objet non initialisé vaut null.
Nos dates sont un peu lourdes ŕ manipuler. Trčs souvent, on veut une
méthode paramétrée pour construire un objet d'une classe. C'est
tellement fréquent qu'il y a une syntaxe particuličre pour le
faire. Ainsi si on écrit
class Date {
int j; /* Jour */
int m; /* Mois */
int a; /* Année */
Date (int jour, int mois, int annee) {
this.j = jour;
this.m = mois;
this.a = annee;
};
on pourra créer les dates simplement avec
static Date berlin = new Date(10, Nov, 1989),
bastille = new Date(14, Juil, 1789);
Un constructeur est donc une méthode (non statique) sans
nom. On indique le type de son résutat (ie le nom de la classe oů il
se trouve) et ses paramčtres. Le corps de la fonction est quelconque,
mais on ne retourne pas explicitement de valeur, puisque son résultat
est toujours l'objet en cours de création. Le constructeur est utilisé
derričre un mot-clé new. Dans le cas oů il n'y a pas de
constructeur explicite, le constructeur par défaut (sans arguments)
réserve juste l'espace mémoire nécessaire pour l'objet
construit. Remarquons que dans le constructeur, on a utilisé le
mot-clé this qui désigne l'objet en cours de création pour bien
comprendre que j, m et a sont des champs de
l'objet construit. Le constructeur se finit donc implicitement par
return this. Mais, ce mot-clé n'était pas vraiment utile. On
aurait pu simplement écrire
class Date {
int j; /* Jour */
int m; /* Mois */
int a; /* Année */
Date (int jour, int mois, int annee) {
j = jour;
m = mois;
a = annee;
};
Un champ peut ętre déclaré statique. Cela signifie qu'il n'existe qu'ŕ un
seul exemplaire dans la classe dont il fait partie. Une donnée statique est
donc attachée ŕ une classe et non aux objets de cette classe. Supposons par
exemple que l'origine des temps (pour le systčme Unix) soit une valeur de
premičre importance, ou que nous voulions compter le nombre de dates crées
avec notre constructeur. On écrirait:
class Date {
int j; /* Jour */
int m; /* Mois */
int a; /* Année */
static final int Jan=1, Fev=2, Mar=3, Avr=4, Mai=5, Juin=6,
Juil=7, Aou=8, Sep=9, Oct=10, Nov=11, Dec=12;
static Date tempsZeroUnix = new Date (1, Jan, 1970);
static int nbInstances = 0;
Date (int jour, int mois, int annee) {
j = jour;
m = mois;
a = annee;
++ nbInstances;
};
Il y a donc deux sortes de données dans une classe, les champs
associés ŕ chaque instance d'un objet (ici les jours, mois et années), et
les champs uniques pour toute la classe (ici les constantes, la date
temps-zéro pour Unxi et le nombre d'utilisateurs). Les variables statiques
sont initialisées au chargement de la classe, les autres dynamiquement en
accédant aux champs de l'objet.
Considérons maintenant les méthodes d'une classe. A nouveau, elles sont de
deux sortes: les méthodes dynamiques et les méthodes statiques. Dans notre
cours, nous avons fortement privilégié cette deuxičme catégorie, car leur
utilisation est trčs proche de celle des fonctions ou procédures de C ou de
Pascal. Les méthodes statiques sont précédées du mot-clé static, les
méthodes dynamiques n'ont pas de préfixe. La syntaxe est celle d'une
fonction usuelle. Prenons le cas de l'impression de notre classe Date.
class Date {
...
static void imprimer (Date d) {
System.out.print ("d = " + d.j + ", " +
"m = " + d.m + ", " +
"a = " + d.a);
}
}
et on pourra imprimer avec des instructions du genre
Date.imprimer (berlin);
Date.imprimer (bastille);
Remarquons qu'on doit qualifier le nom de procédure par le nom de
la classe, si on se trouve dans une autre classe. (Cette syntaxe est
cohérente avec celle des accčs aux champs de données). Dans les langages de
programmation usuels, on retrouve cette notation aussi pour accéder aux
fonctions de modules différents. On peut aussi écrire de męme une fonction
qui teste l'égalité de deux dates
class Date {
...
static boolean equals (Date d1, Date d2) {
return d1.j == d2.j && d1.m == d2.m && d1.a == d2.a;
}
}
Jusqu'ŕ présent, nous avions considéré des objets, des fonctions, et des
classes. Les méthodes non statiques sont le béaba de la programmation objet.
Quelle est l'idée? Comme une classe, un objet a non seulement des champs de
données, mais il contient aussi un vecteur de méthodes. Pour déclencher une
méthode, on passe les paramčtres aux méthodes de l'objet. Ces fonctions ont
la męme syntaxe que les méthodes dynamiques, ŕ une exception prčs: elles ont
aussi le paramčtre implicite this qui est l'objet dont elles sont la
méthode. (Pour accéder aux champs de l'objet, this est facultatif).
Ce changement, qui rend plus proches les fonctions et les données, peut
paraître mineur, mais il est ŕ la base de la programmation objet, car il se
combinera ŕ la notion de sous-classe. Prenons l'exemple des deux méthodes
statiques écrites précédemment. Nous pouvons les réécrire non statiquement
comme suit:
class Date {
...
void print () {
System.out.print ("d = " + this.j + ", " +
"m = " + this.m + ", " +
"a = " + this.a);
}
boolean equals (Date d) {
return this.j == d.j && this.m == d.m && this.a == d.a;
}
}
ou encore sans le mot-clé this non nécessaire ici:
class Date {
...
void print () {
System.out.print ("d = " + j + ", " +
"m = " + m + ", " +
"a = " + a);
}
boolean equals (Date d) {
return j == d.j && m == d.m && a == d.a;
}
}
et on pourra indistinctement écrire
if (!Date.equals(berlin, bastille))
Date.imprimer (berlin);
oů
if (!berlin.equals(bastille))
berlin.print ();
Dans la deuxičme écriture, on passe l'argument (quand il existe) ŕ
la méthode correspondante de l'objet auquel appartient cette méthode. Nous
avons déjŕ utilisé cette notation avec les fonctions prédéfinies de la
librairie. Par exemple println est une méthode associé au flux de
sortie out, qui lui męme est une donnée statique de la classe
System. De męme pour les chaînes de caractčres: la classe
String définit les méthodes length, charAt pour obtenir
la longueur de l'objet chaîne s ou lire le caractčre ŕ la position
i dans s comme suit:
String s = "Oh, la belle chaîne";
if (s.length() > 20)
System.out.println (s.charAt(i));
Il faut savoir que la méthode (publique) spéciale
toString peut ętre pris en compte par le systčme d'écriture
standard. Ainsi, dans le cas des dates, si on avait déclaré,
class Date {
...
public String toString () {
return ("d = " + j + ", " +
"m = " + m + ", " +
"a = " + a);
}
}
on aurait pu seulement écrire
if (!berlin.equals(bastille))
System.out.println (berlin);
Enfin, dans une classe, on peut directement mettre entre accolades des
instructions, éventuellement précédées par le mot-clé static pour
initialiser divers champs ŕ chaque création d'un objet ou au chargement de
la classe.
Faisons trois remarques supplémentaires sur les objets. Primo, un
objet peut ętre passé comme paramčtre d'une procédure, mais alors
seule la référence ŕ l'objet est passée. Il n'y a pas de copie de
l'objet. Donc, on peut éventuellement modifier le contenu de l'objet
dans la procédure. (Pour copier un objet, on peut souvent utiliser la
méthode clone).
| Les objets ne sont jamais copiés implicitement |
Deuxičmement, il n'y a pas d'instruction pour
détruire des objets. Ce n'est pas grave, car le garbage
collector (GC) récupčre automatiquement l'espace mémoire des objets
non utilisés. Cela est fait réguličrement, notamment quand il n'y a
plus de place en mémoire. C'est un service de récupération des
ordures, comme dans la vie courante. Il n'y a donc pas ŕ se soucier de
la dé-allocation des objets. Troisičmement, il est possible de
surcharger les méthodes en faisant varier le type de leurs arguments
ou leur nombre. Nous avons déjŕ vu le cas de println qui
prenait zéro arguments ou un argument de type quelconque (qui était en
fait transformé en chaîne de caractčres avec la méthode
toString). On peut déclarer trčs simplement de telles méthodes
surchargées, par exemple dans le cas des constructeurs:
class Date {
int j; /* Jour */
int m; /* Mois */
int a; /* Année */
Date (int jour, int mois, int annee) {
j = jour; m = mois; a = annee;
Date (long n) {
// Un savant calcul du jour, mois et année ŕ partir du nombre
// de millisecondes depuis l'origine des temps informatiques, ie
// le 1 janvier 1970.
}
Date () {
// idem avec le temps courant System.currentTimeMillis
}
};
Le constructeur adéquat sera appelé en fonction du type ou du
nombre de ses arguments, ici avec trois entiers désignant les jour, mois et
année, ou avec un seul entier long donnant le nombre de milisecondes depuis
le début des temps informatiques, ou sans argument pour avoir la date du
jour courant. (Remarque: compter le temps avec des milisecondes sur 64 bits
reporte le problčme du bug de l'an 2000 ŕ l'an 108, mais ce n'est
pas le cas dans certains systčmes Unix oů le nombre de secondes sur 32 bits
depuis 1970 reporte le problčme ŕ l'an 2038!). Il faut faire attention aux
abus de surcharge, et introduire une certaine logique dans son utilisation,
sinon les programmes deviennent rapidement incompréhensibles. Pire, cela
peut ętre redoutable lorsqu'on combine surcharge et héritage (cf. plus
loin).
| La surcharge est résolue statiquement ŕ la compilation. |
A.2.7 Sous-classes
Le cours n'utilise pratiquement pas la notion de sous-classe, car cette
notion intervient surtout si on fait de la programmation
orientée-objet. Nous mentionnons toutefois bričvement cette notion. Une
classe peut étendre une autre classe. Par exemple, la classe des dates
pourrait ętre refaite en deux systčmes de dates: grégorien ou
révolutionnaire en fonction du nombre de millisecondes (éventuellement
négatif) depuis l'origine des temps informatiques; ou bien une classe étend
une classe standard déjŕ fournie comme celle des applets pour
programmer un navigateur, ou la classe MacLib pour faire le graphique
élémentaire de ce cours; etc. Prenons l'exemple ultra classique de la
classe des points éventuellement colorés, exemple qui a l'avantage d'ętre
court et suffisant pour expliquer la problématique rencontrée. Un point est
représenté par la paire (x,y) de ses coordonnées
class Point {
int x, y;
Point (int x0, int y0) {
x = x0; y = y0;
}
public String toString () {
return "(" + x + ", " + y +")";
}
void move (int dx, int dy) {
x = x + dx;
y = y + dy;
}
}
On considčre deux méthodes pour convertir un point en chaîne de
caractčres (pour l'impression) et une autre move pour bouger un
point, cette derničre méthode étant une procédure qui renvoie donc le type
vide. On peut utiliser des objets de cette classe en écrivant des
instructions de la forme
Point p = new Point(1, 2);
System.out.println (p);
p.move (-1, -1);
System.out.println (p);
Définissons ŕ présent la classe des points colorés avec un champ
supplémentaire couleur, en la déclarant comme une extension, ou
encore une sous-classe, de la classe des points, comme suit:
class PointAvecCouleur extends Point {
int couleur;
PointAvecCouleur (int x0, int y0, int c) {
super (x0, y0); couleur = c;
}
public String toString () {
return "(" + x + ", " + y + ", " + couleur + ")";
}
}
Les champs x et y de l'ancienne classe des points existent
toujours. Le champ couleur est juste ajouté. S'il existait déjŕ un champ
couleur dans la classe Point, on ne ferait que le cacher et l'ancien
champ serait toujours accessible par super.couleur grâce au mot-clé
super. Dans la nouvelle classe, nous avons un constructeur qui prend
un argument supplémentaire pour la couleur. Ce constructeur doit toujours
commencer par un appel ŕ un constructeur de la super-classe (la classe des
points). Si on ne met pas d'appel explicite ŕ un constructeur de cette
classe, l'instruction super() est faite implicitement, et ce
constructeur doit alors exister dans la super classe. Enfin, la méthode
toString est redéfinie pour prendre en compte le nouveau champ pour
la couleur. On utilise les points colorés comme suit
PointAvecCouleur q = new PointAvecCouleur (3, 4, 0xfff);
System.out.println (q);
q.move(10,-1);
System.out.println (q);
La classe des points colorés a donc hérité des champs x et
y et de la méthode move de la classe des points, mais la méthode
toString a été redéfinie. On n'a eu donc qu'ŕ programmer l'incrément
entre les points normaux et les points colorés. C'est le principe de base de
la programmation objet: le contrôle des programmes est dirigé par les
données et leurs modifications. Dans la programmation classique, on doit
changer le corps de beaucoup de fonctions ou de procédures si on change les
déclarations des données, car la description d'un programme est donné par sa
fonctionalité.
Une méthode ne peut redéfinir qu'une méthode de męme type pour ses
paramčtres et résultat. Plus exactement, elle peut redéfinir une méthode
d'une classe plus générale dont les arguments ont un type plus général. Il
est interdit de définir les méthodes préfixées par le mot-clé final.
On ne peut non plus donner des modificateurs d'accčs plus restrictifs, une
méthode publique devant rester publique. Une classe hérite d'une seule
classe (héritage simple). Des langages comme Smalltalk ou C++ autorisent
l'héritage multiple ŕ partir de plusieurs classes, mais les méthodes sont
alors un peu plus délicates ŕ implémenter. L'héritage est bien sűr
transitif. D'ailleurs toutes les classes Java héritent d'une unique classe
Object.
Il se pose donc le problčme de savoir quelle méthode est utilisée pour un
objet donné. C'est toujours la méthode la plus précise qui peut s'appliquer ŕ
l'objet et ŕ ses arguments qui est sélectionnée. Remarquons que ceci n'est
pas forcément dans le corps du programme chargé au moment de la référence,
puisqu'une nouvelle classe peut ętre chargée, et contenir la méthode qui
sera utilisée.
| La résolution des méthodes dynamiques est faite ŕ l'exécution. |
Enfin, il y a une façon de convertir un objet en objet d'une super-classe ou
d'une sous-classe avec la notation dex conversion explicites (déja vu pour
le cas des valeurs numériques). Par exemple
Point p = new Point (10, 10);
PointAvecCouleur q = new PointAvecCouleur (20, 20, ROUGE);
Point p1 = q;
PointAvecCouleur q1 = (PointAvecCouleur) p;
PointAvecCouleur q2 = (PointAvecCouleur) p1;
Aller vers une classe plus générale ne pose pas en général de
difficultés, et le faire explicitement peut forcer la résolution des
surcharges de nom de fonctions, mais l'objet reste le męme. Si on convertit
vers une sous-classe plus restrictive, la machine virtuelle Java vérifie ŕ
l'exécution et peut lever l'exception ClassCastException. Dans
l'exemple précédent seule l'avant-derničre ligne lčvera cette exception.
A.2.8 Tableaux
Les tableaux sont des objets comme les autres. Un champ length
indique leur longueur. L'accčs aux éléments du tableau a s'écrit avec des
crochets, a[i-1] représente i-čme élément. Les tableaux n'ont
qu'une seule dimension, un tableau ŕ deux dimensions est considéré comme un
tableau dont tous les éléments sont des tableaux ŕ une dimension, etc. Si on
accčde en dehors du tableau, une exception est levée. La création d'un
tableau se fait avec le mot-clé new comme pour les objets, mais il
existe une facilité syntaxique pour créer des tableaux ŕ plusieurs
dimensions. Voici par exemple le calcul de la table de vérité de l'union de
deux opérateurs booléens:
static boolean[][] union (boolean a[][], boolean b[][]) {
boolean c[][] = new boolean [2][2];
for (int i = 0; i < 2; ++i)
for (int j = 0; j < 2; ++j)
c[i][j] = a[i][j] || b[i][j];
return c;
}
Pour initialiser un tableau, on peut le faire avec des constantes
litérales:
boolean intersection [][] = {{true, false},{false, false}};
boolean ouExclusif [][] = {{false, true},{true, false}};
Enfin, on peut affecter des objets d'une sous-classe dans un
tableau d'éléments d'une classe plus générale.
A.2.9 Exceptions
Les exceptions sont des objets de toute sous-classe de la classe
Exception. Il existe aussi une classe Error moins utilisée
pour les erreurs systčme. Toutes les deux sont des sous-classes de la classe
Throwable, dont tous les objets peuvent ętre appliqués ŕ l'opérateur
throw, comme suit:
throw e;
Ainsi on peut écrire en se servant de deux constructeurs de la
classe Exception:
throw new Exception();
throw new Exception ("Accčs interdit dans un tableau");
Heureusement, dans les classes des librairies standard, beaucoup
d'exceptions sont déja pré-définies, par exemple
IndexOutOfBoundsExeption. On récupčre une exception par l'instruction
try ...catch. Par exemple
try {
// un programme compliqué
} catch ( IOException e) {
// essayer de réparer cette erreur d'entrée/sortie
}
catch ( Exception e) {
// essayer de réparer cette erreur plus générale
}
Si on veut faire un traitement uniforme en fin de l'instruction
try, que l'on passe ou non par une exception, que le contrôle sorte
ou non de l'instruction par une rupture de séquence comme un return,
break, etc, on écrit
try {
// un programme compliqué
} catch ( IOException e) {
// essayer de réparer cette erreur d'entrée/sortie
}
catch ( Exception e) {
// essayer de réparer cette erreur plus générale
}
finally {
// un peu de nettoyage
}
Il y a deux types d'exceptions. On doit déclarer les exceptions
vérifiées derričre le mot-clé throws dans la signature des fonctions
qui les lčvent. Ce n'est pas la peine pour les exceptions non
vérifiées qui se reconnaissent en appartenant ŕ une sous-classe de la
classe RuntimeException. Ainsi
static int lire () throws IOException, ParseException {
int n;
BufferedReader in =
new BufferedReader(new InputStreamReader(System.in));
System.out.print ("Taille du carré magique, svp?:: ");
n = Integer.parseInt (in.readLine());
if ((n <= 0) || (n > N) || (n % 2 == 0))
erreur ("Taille impossible.");
return n;
}
aurait pu ętre écrit dans l'exemple du carré magique.
A.2.10 Entrées-Sorties
Nous ne considérons que quelques instructions simples permettant de lire ou
écrire dans une fenętre texte ou avec un fichier. System.in et
System.out sont deux champs statiques (donc uniques) de la classe
systčme, qui sont respectivement des InputStream et
PrintStream. Dans cette derničre classe, il y a notamment les
méthodes: flush qui vide les sorties non encore effectuées,
print et println qui impriment sur le terminal leur argument
avec éventuellement un retour ŕ la ligne. Pour l'impression, l'argument de
ces fonctions est quelconque, (éventuellement vide pour la deuxičme). Elles
sont surchargées sur pratiquement tous les types, et transforment leur
argument en chaîne de caractčres. Ainsi:
System.out.println ("x= ") donne x = newline
System.out.println (100) 100 newline:
System.out.print (3.14) 3.14
System.out.print ("3.14") 3.14
System.out.print (true) true
System.out.print ("true") true
Les méthodes des classes InputStream et PrintStream lisent ou
impriment des octets (byte). Il vaut mieux faire des opérations avec
des caractčres Unicode (sur 16 bits, qui comprennent tous les caractčres
internationaux). Pour cela, au lieu de fonctionner avec les flux d'octets
(Stream tout court), on utilise les classes des Reader ou des
Writer, comme InputStreamReader et OutputStreamWriter,
qui manipulent des flux de caractčres. Dans ces classes, il existe de
nombreuses méthodes ou fonctions. Ici, nous considérons les entrées-sorties
avec un tampon (buffer en anglais), qui sont plus efficaces, car elles
regroupent les opérations d'entrées-sorties. C'est pourquoi, on écrit
souvent la ligne cryptique:
struct Noeud {
BufferedReader in =
new BufferedReader(new InputStreamReader(System.in));
qui construit, ŕ partir du flux de caractčres System.in
(désignant la fenętre d'entrée de texte par défaut), un flux de caractčres,
puis un flux de caractčres avec tampon (plus efficace). Dans cette derničre
classe, on lit les caractčres par read() ou readLine(). Par
convention, read() retourne -1 quand la fin de l'entrée est détectée
(comme en C). C'est pourquoi le type de son résultat est un entier (et non
un caractčre), puisque -1 ne peut pas ętre du type caractčre. Pour lire
l'entrée terminal et l'imprimer immédiatement, on fait donc:
import java.io.*;
static void copie () throws Exception {
BufferedReader in =
new BufferedReader(new InputStreamReader(System.in));
int c;
while ((c = in.read()) != -1)
System.out.println(c);
System.out.flush();
}
Remarquons l'idiome pour lire un caractčre. Il s'agit d'un effet
de bord dans le prédicat du while. On fait l'affectation c =
in.read() qui retourne comme résultat la valeur de la partie droite (le
caractčre lu) et on teste si cette valeur vaut -1.
On peut aussi manipuler des fichiers, grâce aux classes fichiers
File. Ainsi le programme précédent se réécrit pour copier un fichier
source de nom s dans un autre destination de nom d.
import java.io.*;
static void copieDeFichiers (String s, String d) throws Exception {
File src = new File (s);
if ( !src.exists() || !src.canRead())
erreur ("Lecture impossible de " + s);
BufferedReader in = new BufferedReader(new FileReader(src));
File dest = new File (d);
if ( !dest.canWrite())
erreur ("Ecriture impossible de " + d);
BufferedWriter out = new BufferedWriter(new FileWriter(dest));
maCopie (in, out);
in.close();
out.close();
}
static void maCopie (BufferedReader in, BufferedWriter out)
throws IOException {
int c;
while ((c = in.read()) != -1)
out.write(c);
out.flush();
}
La procédure de copie ressemble au programme précédent, au
changement prčs de print en write, car nous n'avons pas voulu
utiliser la classe Printer, ce qui était faisable. Remarquons que les
entrées sorties se sont simplement faites avec les fichiers en suivant un
shéma quasi identique ŕ celui utilisé pour le terminal. La seule différence
vient de l'association entre le nom de fichier et les flux de caractčres
tamponnés. D'abord le nom de fichier est transformé en objet File sur
lequel plusieurs opérations sont possibles, comme vérifier l'existence ou
les droits d'accčs en lecture ou en écriture. Puis on construit un objet de
flux de caractčres dans les classes FileReader et FileWriter,
et enfin des objets de flux de caractčres avec tampon. La procédure de copie
est elle identique ŕ celle vue précédemment.
On peut donc dire que l'entrée standard System.in (de la fenętre de
texte), la sortie standard System.out (dans la fenętre de texte), et
la sortie standard des erreurs System.err (qui n'a vraiment de sens
que dans le systčme Unix) sont comme des fichiers particuliers. Les
opérations de lecture ou d'écriture étant les męmes. Seule la construction
du flux de caractčres tamponné varie.
Enfin, on peut utiliser mark, skip et reset pour se
positionner ŕ une position précise dans un fichier.
A.2.11 Fonctions graphiques
Les fonctions sont inspirées de la libraire QuickDraw du Macintosh,
mais fonctionnent aussi sur les stations Unix. Sur Macintosh, une
fenętre Drawing permet de gérer un écran typiquement de 1024
× 768 points. L'origine du systčme de coordonnées est en haut et
ŕ gauche. L'axe des x va classiquement de la gauche vers la droite,
l'axe des y va plus curieusement du haut vers le bas (c'est une
vieille tradition de l'informatique, dure ŕ remettre en cause). En
QuickDraw, x et y sont souvent appelés h (horizontal) et
v (vertical). Il y a une notion de point courant et de crayon
avec une taille et une couleur courantes. On peut déplacer le crayon,
en le levant ou en dessinant des vecteurs par les fonctions suivantes
moveTo (x, y) - Déplace le crayon aux coordonnées
absolues
x, y.
move (dx, dy) - Déplace le crayon en relatif de
dx, dy.
lineTo (x, y) - Trace une ligne depuis le point courant
jusqu'au point de coordonnées
x, y.
line (dx, dy) - Trace le vecteur (
dx, dy)
depuis le point courant.
penPat(pattern) - Change la couleur du crayon:
white, black, gray, dkGray (dark
gray), ltGray (light gray).
penSize(dx, dy) - Change la taille du crayon. La taille
par défaut est (1, 1). Toutes les opérations de tracé peuvent se
faire avec une certaine épaisseur du crayon.
penMode(mode) - Change le mode d'écriture:
patCopy (mode par défaut qui efface ce sur quoi on
trace), patOr (mode Union, i.e. sans effacer ce sur quoi on
trace), patXor (mode Xor, i.e. en inversant ce sur quoi on
trace).
Certaines opérations sont possibles sur les rectangles. Un
rectangle r a un type prédéfini Rect. Ce type est une classe
qui a le format suivant
public class Rect {
short left, top, right, bottom;
}
Fort heureusement, il n'y a pas besoin de connaître le
format internes des rectangles, et on peut faire simplement les
opérations graphiques suivantes sur les rectangles
setRect(r, g, h, d, b) - fixe les coordonnées (gauche,
haut, droite, bas) du rectangle
r. C'est équivalent ŕ faire
les opérations r.left := g;, r.top := h;,
r.right := d;, r.bottom := b.
unionRect(r1, r2, r) - définit le rectangle
r
comme l'enveloppe englobante des rectangles r1 et r2.
frameRect(r) - dessine le cadre du rectangle
r
avec la largeur, la couleur et le mode du crayon courant.
paintRect(r) - remplit l'intérieur du rectangle
r
avec la couleur courante.
invertRect(r) - inverse la couleur du rectangle
r.
eraseRect(r) - efface le rectangle
r.
fillRect(r,pat) - remplit l'intérieur du rectangle
r avec la couleur pat.
drawChar(c), drawString(s)- affiche le caractčre
c ou la chaîne s au point courant dans la fenętre
graphique. Ces fonctions diffčrent de write ou writeln
qui écrivent dans la fenętre texte.
frameOval(r) - dessine le cadre de l'ellipse inscrite
dans le rectangle
r avec la largeur, la couleur et le mode du
crayon courant.
paintOval(r) - remplit l'ellipse inscrite dans le
rectangle
r avec la couleur courante.
invertOval(r) - inverse l'ellipse inscrite dans
r.
eraseOval(r) - efface l'ellipse inscrite dans
r.
fillOval(r,pat) - remplit l'intérieur l'ellipse inscrite
dans
r avec la couleur pat.
frameArc(r,start,arc) - dessine l'arc de l'ellipse
inscrite dans le rectangle
r démarrant ŕ l'angle start
et sur la longueur définie par l'angle arc.
frameArc(r,start,arc) - peint le camembert correspondant
ŕ l'arc précédent .... Il y a aussi des fonctions pour les
rectangles avec des coins arrondis.
button - est une fonction qui renvoie la valeur vraie si
le bouton de la souris est enfoncé, faux sinon.
getMouse(p) - renvoie dans
p le point de
coordonnées (p.h, p.v) courantes du curseur.
getPixel(p) - donne la couleur du point
p.
Répond un booléen: false si blanc, true. si noir.
hideCursor(), showCursor() - cache ou remontre le curseur.
class Point {
short h, v;
Point(int h, int v) {
h = (short)h;
v = (short)v;
}
}
class MacLib {
static void setPt(Point p, int h, int v) {..}
static void addPt(Point src, Point dst) {...}
static void subPt(Point src, Point dst) {...}
static boolean equalPt(Point p1, Point p2) {...}
...
}
Et les fonctions correspondantes (voir page
X)
static void setRect(Rect r, int left, int top, int right, int bottom)
static void unionRect(Rect src1, Rect src2, Rect dst)
static void frameRect(Rect r)
static void paintRect(Rect r)
static void eraseRect(Rect r)
static void invertRect(Rect r)
static void frameOval(Rect r)
static void paintOval(Rect r)
static void eraseOval(Rect r)
static void invertOval(Rect r)
static void frameArc(Rect r, int startAngle, int arcAngle)
static void paintArc(Rect r, int startAngle, int arcAngle)
static void eraseArc(Rect r, int startAngle, int arcAngle)
static void invertArc(Rect r, int startAngle, int arcAngle)
static boolean button()
static void getMouse(Point p)
Toutes ces définitions sont aussi sur poly dans le fichier
/usr/local/lib/MacLib-java/MacLib.java
On veillera ŕ avoir cette classe dans l'ensemble des classes chargeables
(variable d'environnement CLASSPATH). Le programme suivant est un
programme qui fait rebondir une balle dans un rectangle, premičre étape vers
un jeu de pong.
class Pong extends MacLib {
static final int C = 5, // Le rayon de la balle
X0 = 5, X1 = 250,
Y0 = 5, Y1 = 180;
static void getXY (Point p) {
int N = 2;
Rect r = new Rect();
int x, y;
while (!button()) // On attend le bouton enfoncé
;
while (button()) // On attend le bouton relâché
;
getMouse(p); // On note les coordonnées du pointeur
x = p.h;
y = p.v;
setRect(r, x - N, y - N, x + N, y + N);
paintOval(r); // On affiche le point pour signifier la
lecture
}
public static void main (String args[]) {
int x, y, dx, dy;
Rect r = new Rect();
Rect s = new Rect();
Point p = new Point();
int i;
initQuickDraw(); // Initialisation du graphique
setRect(s, 50, 50, X1 + 100, Y1 + 100);
setDrawingRect(s);
showDrawing();
setRect(s, X0, Y0, X1, Y1);
frameRect(s); // Le rectangle de jeu
getXY(p); // On note les coordonnées du pointeur
x = p.h; y = p.v;
dx = 1; // La vitesse initiale
dy = 1; // de la balle
for (;;) {
setRect(r, x - C, y - C, x + C, y + C);
paintOval(r); // On dessine la balle en x,y
x = x + dx;
if (x - C <= X0 + 1 || x + C >= X1 - 1)
dx = -dx;
y = y + dy;
if (y - C <= Y0 + 1 || y + C >= Y1 - 1)
dy = -dy;
for (i = 0; i < 2500; ++i)
; // On temporise
invertOval(r); // On efface la balle
}
}
}
A.3 Syntaxe BNF de Java
Ce qui suit est une syntaxe sous forme BNF (Backus Naur Form).
Chaque petit paragraphe est la définition souvent récursive d'un fragment de
syntaxe dénommée par un nom (malheureusement en anglais). Chaque ligne
correspond ŕ différentes définitions possibles. L'indice optional
sera mis pour signaler l'aspect facultatif de l'objet indicée. Certains
objets (token) seront supposée préedéfinis: IntegerLiteral
pour une constante entičre, Identifier pour tout identificateur,
...La syntaxe du langage ne garantit pas la concordance des types,
certaines phrases pouvant ętre syntaxiquement correctes, mais fausses pour
les types.
Goal:
CompilationUnit
A.3.1 Contantes littérales
Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
A.3.2 Types, valeurs, et variables
Type:
PrimitiveType
ReferenceType
PrimitiveType:
NumericType
boolean
NumericType:
IntegralType
FloatingPointType
IntegralType: one of
byte short int long char
FloatingPointType: one of
float double
ReferenceType:
ClassOrInterfaceType
ArrayType
ClassOrInterfaceType:
Name
ClassType:
ClassOrInterfaceType
InterfaceType:
ClassOrInterfaceType
ArrayType:
PrimitiveType [ ]
Name [ ]
ArrayType [ ]
A.3.3 Noms
Name:
SimpleName
QualifiedName
SimpleName:
Identifier
QualifiedName:
Name . Identifier
A.3.4 Packages
CompilationUnit:
PackageDeclaration$_opt$ ImportDeclarations$_opt$ TypeDeclarations$_opt$
ImportDeclarations:
ImportDeclaration
ImportDeclarations ImportDeclaration
TypeDeclarations:
TypeDeclaration
TypeDeclarations TypeDeclaration
PackageDeclaration:
package Name ;
ImportDeclaration:
SingleTypeImportDeclaration
TypeImportOnDemandDeclaration
SingleTypeImportDeclaration:
import Name ;
TypeImportOnDemandDeclaration:
import Name . * ;
TypeDeclaration:
ClassDeclaration
InterfaceDeclaration
;
Modifiers:
Modifier
Modifiers Modifier
Modifier: one of
public protected private
static
abstract final native synchronized transient volatile
A.3.5 Classes
Déclaration de classe
ClassDeclaration:
Modifiers$_opt$ class Identifier Super$_opt$ Interfaces$_opt$ ClassBody
Super:
extends ClassType
Interfaces:
implements InterfaceTypeList
InterfaceTypeList:
InterfaceType
InterfaceTypeList , InterfaceType
ClassBody:
{ClassBodyDeclarations$_opt$ }
ClassBodyDeclarations:
ClassBodyDeclaration
ClassBodyDeclarations ClassBodyDeclaration
ClassBodyDeclaration:
ClassMemberDeclaration
StaticInitializer
ConstructorDeclaration
ClassMemberDeclaration:
FieldDeclaration
MethodDeclaration
Déclarations de champs
FieldDeclaration:
Modifiers$_opt$ Type VariableDeclarators ;
VariableDeclarators:
VariableDeclarator
VariableDeclarators , VariableDeclarator
VariableDeclarator:
VariableDeclaratorId
VariableDeclaratorId = VariableInitializer
VariableDeclaratorId:
Identifier
VariableDeclaratorId [ ]
VariableInitializer:
Expression
ArrayInitializer
Déclarations de méthodes
MethodDeclaration:
MethodHeader MethodBody
MethodHeader:
Modifiers$_opt$ Type MethodDeclarator Throws$_opt$
Modifiers$_opt$ void MethodDeclarator Throws$_opt$
MethodDeclarator:
Identifier ( FormalParameterList$_opt$ )
MethodDeclarator [ ]
FormalParameterList:
FormalParameter
FormalParameterList , FormalParameter
FormalParameter:
Type VariableDeclaratorId
Throws:
throws ClassTypeList
ClassTypeList:
ClassType
ClassTypeList , ClassType
MethodBody:
Block
;
Initialieurs statiques
StaticInitializer:
static Block
Déclarations de constructeurs
ConstructorDeclaration:
Modifiers$_opt$ ConstructorDeclarator Throws$_opt$ ConstructorBody
ConstructorDeclarator:
SimpleName ( FormalParameterList$_opt$ )
ConstructorBody:
{ExplicitConstructorInvocation$_opt$ BlockStatements$_opt$ }
ExplicitConstructorInvocation:
this ( ArgumentList$_opt$ ) ;
super ( ArgumentList$_opt$ ) ;
A.3.6 Interfaces
InterfaceDeclaration:
Modifiers$_opt$ interface Identifier ExtendsInterfaces$_opt$ InterfaceBody
ExtendsInterfaces:
extends InterfaceType
ExtendsInterfaces , InterfaceType
InterfaceBody:
{InterfaceMemberDeclarations$_opt$ }
InterfaceMemberDeclarations:
InterfaceMemberDeclaration
InterfaceMemberDeclarations InterfaceMemberDeclaration
InterfaceMemberDeclaration:
ConstantDeclaration
AbstractMethodDeclaration
ConstantDeclaration:
FieldDeclaration
AbstractMethodDeclaration:
MethodHeader ;
A.3.7 Tableaux
ArrayInitializer:
{VariableInitializers$_opt$ ,$_opt$ }
VariableInitializers:
VariableInitializer
VariableInitializers , VariableInitializer
A.3.8 Blocs et instructions
Block:
{BlockStatements$_opt$ }
BlockStatements:
BlockStatement
BlockStatements BlockStatement
BlockStatement:
LocalVariableDeclarationStatement
Statement
LocalVariableDeclarationStatement:
LocalVariableDeclaration ;
LocalVariableDeclaration:
Type VariableDeclarators
Statement:
StatementWithoutTrailingSubstatement
LabeledStatement
BlockStatementsBlockStatementsIfThenStatement
IfThenElseStatement
WhileStatement
ForStatement
StatementNoShortIf:
StatementWithoutTrailingSubstatement
LabeledStatementNoShortIf
IfThenElseStatementNoShortIf
WhileStatementNoShortIf
ForStatementNoShortIf
StatementWithoutTrailingSubstatement:
Block
EmptyStatement
ExpressionStatement
SwitchStatement
DoStatement
BreakStatement
ContinueStatement
ReturnStatement
SynchronizedStatement
ThrowStatement
TryStatement
EmptyStatement:
;
LabeledStatement:
Identifier : Statement
LabeledStatementNoShortIf:
Identifier : StatementNoShortIf
ExpressionStatement:
StatementExpression ;
StatementExpression:
Assignment
PreIncrementExpression
PreDecrementExpression
PostIncrementExpression
PostDecrementExpression
MethodInvocation
ClassInstanceCreationExpression
IfThenStatement:
if ( Expression ) Statement
IfThenElseStatement:
if ( Expression ) StatementNoShortIf else Statement
IfThenElseStatementNoShortIf:
if ( Expression ) StatementNoShortIf else StatementNoShortIf
SwitchStatement:
switch ( Expression ) SwitchBlock
SwitchBlock:
{SwitchBlockStatementGroups$_opt$ SwitchLabels$_opt$ }
SwitchBlockStatementGroups:
SwitchBlockStatementGroup
SwitchBlockStatementGroups SwitchBlockStatementGroup
SwitchBlockStatementGroup:
SwitchLabels BlockStatements
SwitchLabels:
SwitchLabel
SwitchLabels SwitchLabel
SwitchLabel:
case ConstantExpression :
default :
WhileStatement:
while ( Expression ) Statement
WhileStatementNoShortIf:
while ( Expression ) StatementNoShortIf
DoStatement:
do Statement while ( Expression ) ;
ForStatement:
for ( ForInit$_opt$ ; Expression$_opt$ ; ForUpdate$_opt$ )
Statement
ForStatementNoShortIf:
for ( ForInit$_opt$ ; Expression$_opt$ ; ForUpdate$_opt$ )
StatementNoShortIf
ForInit:
StatementExpressionList
LocalVariableDeclaration
ForUpdate:
StatementExpressionList
StatementExpressionList:
StatementExpression
StatementExpressionList , StatementExpression
BreakStatement:
break Identifier$_opt$ ;
ContinueStatement:
continue Identifier$_opt$ ;
ReturnStatement:
return Expression$_opt$ ;
ThrowStatement:
throw Expression ;
SynchronizedStatement:
synchronized ( Expression ) Block
TryStatement:
try Block Catches
try Block Catches$_opt$ Finally
Catches:
CatchClause
Catches CatchClause
CatchClause:
catch ( FormalParameter ) Block
Finally:
finally Block
A.3.9 Expressions
Primary:
PrimaryNoNewArray
ArrayCreationExpression
PrimaryNoNewArray:
Literal
this
( Expression )
ClassInstanceCreationExpression
FieldAccess
MethodInvocation
ArrayAccess
ClassInstanceCreationExpression:
new ClassType ( ArgumentList$_opt$ )
ArgumentList:
Expression
ArgumentList , Expression
ArrayCreationExpression:
new PrimitiveType DimExprs Dims$_opt$
new ClassOrInterfaceType DimExprs Dims$_opt$
DimExprs:
DimExpr
DimExprs DimExpr
DimExpr:
[ Expression ]
Dims:
[ ]
Dims [ ]
FieldAccess:
Primary . Identifier
super . Identifier
MethodInvocation:
Name ( ArgumentList$_opt$ )
Primary . Identifier ( ArgumentList$_opt$ )
super . Identifier ( ArgumentList$_opt$ )
ArrayAccess:
Name [ Expression ]
PrimaryNoNewArray [ Expression ]
PostfixExpression:
Primary
Name
PostIncrementExpression
PostDecrementExpression
PostIncrementExpression:
PostfixExpression ++
PostDecrementExpression:
PostfixExpression --
UnaryExpression:
PreIncrementExpression
PreDecrementExpression
+ UnaryExpression
- UnaryExpression
UnaryExpressionNotPlusMinus
PreIncrementExpression:
++ UnaryExpression
PreDecrementExpression:
-- UnaryExpression
UnaryExpressionNotPlusMinus:
PostfixExpression
UnaryExpression
! UnaryExpression
CastExpression
CastExpression:
( PrimitiveType Dims$_opt$ ) UnaryExpression
( Expression ) UnaryExpressionNotPlusMinus
( Name Dims ) UnaryExpressionNotPlusMinus
MultiplicativeExpression:
UnaryExpression
MultiplicativeExpression * UnaryExpression
MultiplicativeExpression / UnaryExpression
MultiplicativeExpression
AdditiveExpression:
MultiplicativeExpression
AdditiveExpression + MultiplicativeExpression
AdditiveExpression - MultiplicativeExpression
ShiftExpression:
AdditiveExpression
ShiftExpression << AdditiveExpression
ShiftExpression >> AdditiveExpression
ShiftExpression >>> AdditiveExpression
RelationalExpression:
ShiftExpression
RelationalExpression < ShiftExpression
RelationalExpression > ShiftExpression
RelationalExpression <= ShiftExpression
RelationalExpression >= ShiftExpression
RelationalExpression instanceof ReferenceType
EqualityExpression:
RelationalExpression
EqualityExpression == RelationalExpression
EqualityExpression != RelationalExpression
AndExpression:
EqualityExpression
AndExpressionEqualityExpression
ExclusiveOrExpression:
AndExpression
ExclusiveOrExpression ^ AndExpression
InclusiveOrExpression:
ExclusiveOrExpression
InclusiveOrExpression | ExclusiveOrExpression
ConditionalAndExpression:
InclusiveOrExpression
ConditionalAndExpressionInclusiveOrExpression
ConditionalOrExpression:
ConditionalAndExpression
ConditionalOrExpression || ConditionalAndExpression
ConditionalExpression:
ConditionalOrExpression
ConditionalOrExpression ? Expression : ConditionalExpression
AssignmentExpression:
ConditionalExpression
Assignment
Assignment:
LeftHandSide AssignmentOperator AssignmentExpression
LeftHandSide:
Name
FieldAccess
ArrayAccess
AssignmentOperator: one of
= *= /=
Expression:
AssignmentExpression
ConstantExpression:
Expression
Bibliographie Java
- [j1] Exploring Java, 2nd edition, Pat Niemeyer et
Joshua Peck 628 pages, O'Reilly, ISBN: 1-56592-271-9. 1997.
- [j2] The Java Language Specification, James Gosling,
Bill Joy et Guy Steele, Addison Wesley, ISBN: 0-201-63456-2. 1996.
- [j3] Java in a Nutshell, David Flanagan, O'Reilly,
ISBN: 1-56592-262-X, 1997.
- [j4] Java examples in a Nutshell, David Flanagan,
O'Reilly, ISBN: 1-56592-371-5. 1997.