jean-jacques.levy@inria.fr
2 février 1998
Les supports de cours sont enhttp://www.polytechnique.fr/poly/edu/informatique/ http://www.polytechnique.fr/poly/~levy/
Livres:
Introduction
Expressions régulières dans Unix
awk, sed, ed, grep, sh
ont des expressions régulières dans leurs arguments. Pour le shell,
* répétition quelconque de caractères
? tout caractère
[az] union des caractères a ou b
[a-p] tous les caractères entre a et p
Exemples:
% ls *.c % ls *[ab][0-2]*.ml % ls ?emacs?Expressions régulières dans sed
En sed, une expression e régulière est:
| c | caractère quelconque à matcher |
^ |
au début pour le caractère nul début de ligne |
$ |
à la fin pour le caractère nul fin de ligne |
. |
pour tout caractère sauf le newline du bout |
e'* |
pour répéter l'expression e' |
[s] |
pour matcher tout caractère de la chaîne s |
[^s] |
pour matcher tout caractère pas dans la chaîne s |
| e'e'' |
Exemples:
% sed -e 's/aa*/a/g' % sed -e '/Ca[^m]*ml/d'
Expression régulières dans awk
Interpréteur C guidé par des expressions régulières. Un programme est une suite de paires (expression régulière, programme C):
pattern1 {action1}
pattern2 {action2}
etc
Deux motifs spéciaux: BEGIN et END pour désigner le début et la fin du fichier.
En outre, la ligne est délimitée en plusieurs champs par \t (ou
autre caractère donné en option), et les actions peuvent manipuler les
champs par $1, $2, etc. Il y a aussi des tableaux
associatifs accessibles par le contenu.
Awk >> Excel.
Exemple de programme Awk
awk -F: 'BEGIN {
code["Prog. L"] = "BD";
code["BdD"] = "CP";
code["Cal. Par."] = "PL";
code["Algo NP"] = "AP";
} {if (NF >= 13){
num = $1; cie = $2; unknown = $8;
nom = $3; prenom = $4; nom = nom "(" prenom ")";
cp = $5; voie = $6; svoie = $7;
maj1 = $9; maj2 = "info";
choix1 = code[$11];
choix2 = code[$12];
choix3 = code[$13];
printf ( "%-23s: %-11s: %s: %s: %s: \n", \
nom, \
maj1, \
choix1, \
choix2, \
choix3);
};}' maj2.txt
Expressions régulières en Perl
Perl est un shell avec des sous-programmes. Il a des tableaux associatifs et des expressions régulières (comme awk) qui peuvent intervenir dans les conditions booléennes, grâce à 2 opérateurs: m// pour matcher une expression, ou s// idem avec remplacement.
Perl n'est pas typé.
Perl est très utilisé dans les cgi-bin qui sont les programmes appelés par le Web pour les formulaires, etc.
Analyseurs lexicaux
Un compilateur commence par transformer le flux de caractères d'entrée en une suite d'entités plus abstraites: les lexèmes. Typiquement, il saute les blancs, les tabulations, les newline, et les commentaires. Les lexèmes sont par exemple les
identificateurs,
nombres,
chaînes de caractères,
opérateurs
Analyseurs lexicaux (2)
Chaque lexème a sa syntaxe donnée par une expression régulière:
identificateur = lettre (lettre ou chiffre)*
nombre = chiffre (chiffre)*
chaîne = "(caractère autre que ")*"
opérateur = symbole non alphanumérique
Il suffit donc d'un automate fini pour faire l'Analyse lexicale. Comment construire cet automate?
Lex
Lex (Lesk et Schmidt) est un utilitaire Unix qui prend des expressions régulières en entrée et qui produit les tables d'un automate fini déterministe qui reconnait le langage correspondant.
Un programme Lex a la forme suivante:
| définitions | |
| %% | |
| pattern1 action1 | |
| pattern2 action2 | |
| ... | |
| %% | |
| programmes de l'utilisateur |
Lexer pour bc levy/m2/bc/scan.l
%{
#include "bcdefs.h"
#include "y.tab.h"
#include "global.h"
#include "proto.h"
%}
DIGIT [0-9A-F]
LETTER [a-z]
%%
scale return(Scale);
ibase return(Ibase);
obase return(Obase);
"+"|"-"|";"|"("|")"|"{"|"}"|"["|"]"|","|"^" {
yylval.c_value = yytext[0]; return((int)yytext[0]); }
&& { return(AND); }
\|\| { return(OR); }
"!" { return(NOT); }
"*"|"/"|"%" { yylval.c_value = yytext[0]; return(MUL_OP); }
"="|\+=|-=|\*=|\/=|%=|\^= {
yylval.c_value = yytext[0]; return(ASSIGN_OP); }
=\+|=-|=\*|=\/|=%|=\^ { yylval.c_value = '='; yyless (1);
return(ASSIGN_OP); }
[ \t]+ { /* ignore spaces and tabs */ }
[a-z][a-z0-9_]* {
yylval.s_value = strcopyof(yytext); return(NAME); }
\"[^\"]*\" {
char *look;
yylval.s_value = strcopyof(yytext);
for (look = yytext; *look != 0; look++)
if (*look == '\n') line_no++;
return(STRING);
}
{DIGIT}({DIGIT}|\\\n)*
("."({DIGIT}|\\\n)*)?|"."(\\\n)*{DIGIT}({DIGIT}|\\\n)* {
...
}
. yyerror ("illegal character: %s",yytext);
%%
Camllex
La structure d'un lexer est identique à celle demandée par Lex.
{ header }
rule entrypoint =
parse pattern_1 { action_1 }
| ...
| pattern_n { action_n }
and entrypoint =
parse ...
and ...
;;
Quelques exemples de grammaires context-free
Grammaires contex-free
Ce sont les grammaires de type 2, dont les règles sont toutes
de la forme ![]() où
où ![]() ,
, ![]() .
.
Arbre syntaxique
Arbre dont la racine est étiqueté par l'axiome de la grammaire, les
noeuds par des non-terminales et les feuilles par des terminales. Si
![]() est une règle de la grammaire, alors les lettres de
est une règle de la grammaire, alors les lettres de
![]() peuvent étiqueter les fils (dans l'ordre) des noeuds de A.
peuvent étiqueter les fils (dans l'ordre) des noeuds de A.
Tout mot w est accepté par la grammaire ssi il existe un arbre syntaxique dont les feuilles forment w. On vérifie facilement que cette condition équivaut à dire qu'il existe une dérivation à partir de l'axiome.
Plusieurs dérivations peuvent correspondre à un même arbre (qui représente en fait une classe de permutation de dérivations produisant une chaîne donnée).
Grammaires ambigues
Plusieurs arbres syntaxiques peuvent aboutir à la même chaîne. On dit alors que la grammaire est ambigue. Par exemple:
![]()
![]()
Si on considère le mot
![]()
a deux arbres syntaxiques différents.
L'exemple des expressions arithmétiques
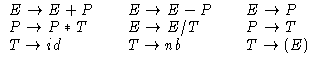
L'arbre syntaxique de a * (b +1 ) est:
Syntaxe abstraite
L'arbre de syntaxe abstraite est un arbre d'opérateurs qui ne contient plus que la sémantique de l'expression. Pour a * (b +1 ) c'est:
Pratiquement tous les compilateurs construisent cet arbre avant de générer du code. Il permet de construire des interpréteurs et de faire les différentes analyses.
Yacc
Yacc (Johnson) est un utilitaire Unix qui prend des grammaires en entrée et qui produit les tables d'un analyseur syntaxique qui reconnait le langage correspondant.
Un programme Yacc a la forme suivante:
| déclarations | |
| %% | |
| règle1 règle2 ... | |
| %% | |
| programmes de l'utilisateur |
Parser pour bc levy/m2/bc/scan.y
%{
#include "bcdefs.h"
#include "global.h"
#include "proto.h"
%}
%start program
%union {
char *s_value;
char c_value;
int i_value;
arg_list *a_value;
}
%token <i_value> NEWLINE AND OR NOT
%token <s_value> STRING NAME NUMBER
...
/* Types of all other things. */
%type <i_value> expression return_expression ...
%type <c_value> '+' '-'
...
/* precedence */
%left OR
%left AND
%nonassoc NOT
...
%%
program : ...
expression :
expression '+' expression
{
generate ("+");
$$ = $1 | $3;
}
NUMBER
{
int len = strlen($1);
$$ = 1;
if (len == 1 && *$1 == '0')
generate ("0");
else if (len == 1 && *$1 == '1')
generate ("1");
else
{
generate ("K");
generate ($1);
generate (":");
}
free ($1);
}
'(' expression ')'
{ $$ = $2 | 1; }
...
Camlyacc
/* File parser.mly */
%token <int> INT
%token PLUS MINUS TIMES DIV
%token LPAREN RPAREN
%token EOL
%left PLUS MINUS /* lowest precedence */
%left TIMES DIV /* medium precedence */
%nonassoc UMINUS /* highest precedence */
%start Main /* the entry point */
%type <int> Main
%%
Main:
Expr EOL { $1 }
;
Expr:
INT { $1 }
| LPAREN Expr RPAREN { $2 }
| Expr PLUS Expr { $1 + $3 }
| Expr MINUS Expr { $1 - $3 }
| Expr TIMES Expr { $1 * $3 }
| Expr DIV Expr { $1 / $3 }
| MINUS Expr %prec UMINUS { - $2 }
;
Lexer correspondant
(* File lexer.mll *)
{
#open "parser";;(* The type token is defined in parser.mli *)
exception Eof;;
}
rule Token = parse
[` ` `\t`] { Token lexbuf } (* skip blanks *)
| [`\n` ] { EOL }
| [`0`-`9`]+ { INT(int_of_string (get_lexeme lexbuf)) }
| `+` { PLUS }
| `-` { MINUS }
| `*` { TIMES }
| `/` { DIV }
| `(` { LPAREN }
| `)` { RPAREN }
| eof { raise Eof }
;;
Programme principal
(* File calc.ml *)
try
let lexbuf = lexing__create_lexer_channel std_in in
while true do
let result = parser__Main lexer__Token lexbuf in
print_int result; print_newline(); flush std_out
done
with Eof ->
()
;;
On compile le tout en tapant les ordres suivants au niveau shell.
camllex lexer.mll # generates lexer.ml camlyacc parser.mly # generates parser.ml and parser.mli camlc -c parser.mli camlc -c lexer.ml camlc -c parser.ml camlc -c calc.ml camlc -o calc lexer.zo parser.zo calc.zoLes modules Camllex et Camlyacc
Dans l'exemple précédent:
lexing__create_lexer_channel crée un canal d'entrée attaché à
stdin, sur le lexer lexer__Token décrit en camllex pourra
fonctionner.
Le lexer retourne les valeurs EOL, INT, PLUS, etc
qui sont les constructeurs d'un type token généré par camlyacc dans
l'interface parser.mli. INT est un constructeur unaire qui
prend un entier en argument.
En yacc, des expressions Caml sont attachées à chaque règle, et retournées comme valeur de la non-terminale membre gauche de la règle. Les valeurs associés aux lettres des parties droites sont notées $1, $2, etc en fonction de leur ordre d'apparition.
Formes normales de grammaires
Prop 1 Soit ![]() générant un
langage non vide. Alors on peut trouver une grammaire équivalente
G1 telle que pour toute non-terminale A de G1, il existe
générant un
langage non vide. Alors on peut trouver une grammaire équivalente
G1 telle que pour toute non-terminale A de G1, il existe ![]() tel que
tel que ![]() .
.
Prop 2 Soit L un langage context-free. Alors il existe une
grammaire G générant L telle que pour toute non-terminale A de
G, il existe une dérivation ![]() où w1, w2, w3 sont des chaines terminales.
où w1, w2, w3 sont des chaines terminales.
Prop 3 Soit G une grammaire context-free. Si ![]() ,alors il existe une dérivation gauche (ie dérivant la non-terminale
toujours la plus à gauche) donnant w.
,alors il existe une dérivation gauche (ie dérivant la non-terminale
toujours la plus à gauche) donnant w.
Formes normales de grammaires (2)
Prop 4 Soit G une grammaire context-free, on peut trouver
une grammaire équivalente sans aucune règle de la forme ![]() , où
A et B sont deux non-terminales.
, où
A et B sont deux non-terminales.
Forme normale de Chomsky
Tout langage context-free peut être généré par une grammaire dont
toutes les règles sont de la forme ![]() ou
ou ![]() où A,
B sont non-terminales, et a est terminale.
où A,
B sont non-terminales, et a est terminale.
Prop 5 Appelons A-règle toute règle dont A est le membre
gauche. Si ![]() est une A-règle et
est une A-règle et ![]() est l'ensemble des
B-règles. Alors la grammaire G1 obtenue en remplaçant la règle
est l'ensemble des
B-règles. Alors la grammaire G1 obtenue en remplaçant la règle ![]() par
par ![]() est équivalente.
est équivalente.
Formes normales de grammaires (3)
Prop 4 Soit G une grammaire context-free Soit ![]() l'ensemble des A-règles dont A est
le symbole le plus à gauche. Soit
l'ensemble des A-règles dont A est
le symbole le plus à gauche. Soit ![]() ,
, ![]()
![]() l'ensemble des A-règles restantes. Alors on peut trouver
une grammaire équivalente, dont toutes les A-règles sont de la forme
l'ensemble des A-règles restantes. Alors on peut trouver
une grammaire équivalente, dont toutes les A-règles sont de la forme
![]() ,
, ![]() ,
, ![]() ,
, ![]() où Z est un nouveau symbole non terminal.
où Z est un nouveau symbole non terminal.
Forme normale de Greibach
Toute langage context-free peut être généré par une grammaire dont
toute les règles sont de la forme ![]() où a est une
terminale et
où a est une
terminale et ![]() ,
, ![]() .
.
Lemme de l'étoile pour les langages réguliers
Théorème Soit L un langage régulier. Il existe p ne
dépendant que de L tel que pour tout mot z de L dont la longueur
|z| excède p, il existe une décomposition
z = uvw
avec ![]() ,
, ![]() , et pour tout n, uvnw est
dans L.
, et pour tout n, uvnw est
dans L.
Exercice Montrer que le langage suivants n'est pas régulier
![]()
Lemme de la pompe pour les langages context-free
Théorème Soit L un langage context-free. Il existe p et
q dépendant de L tel que pour tout mot z de L dont la longueur
|z| excède p, il existe une décomposition
z = uvwxy
avec ![]() ,
, ![]() , et pour tout n, uvnwxny est
dans L.
, et pour tout n, uvnwxny est
dans L.
Exercice Montrer que les langages suivants ne sont pas context-free
![]()
![]()
![]()
Montrer que tout langage context-free sur un alphabet à une lettre est régulier.
Exercices
Exemple:
set x = 25 ;; set y = 228 ;; set z = x ** 4 - y / (1 - x) ;; 2*z ;; plot f(x) = cos (x ** 2);;