Le code correcteur d'erreurs du CD audio
Sujet proposé par Nicolas Sendrier
Nicolas.sendrier@inria.fr
1 Présentation générale
Le standard du disque compact audio comporte un code correcteur
d'erreurs appelé CIRC (Cross Interleaved Reed-Solomon Code). Ce
code a pour but de lutter contre les erreurs de lecture. Ces erreurs
peuvent provenir d'imprécisions mécaniques, de défauts microscopiques
du support, de traces de doigts, de rayures ...
Pour combattre ces dégradations de l'information, un octet sur quatre
inscrits sur le CD est redondant et sert à corriger ces erreurs.
2 Le code CIRC
Le schéma de codage du CD audio utilise deux codes de Reed-Solomon,
C1 = RS(28,24) et C2 = RS(32,28) sur F256 (le corps à 256
éléments). L'écriture RS(n,k) est utilisée pour désigner un
sous-espace vectoriel de dimension k≤ n de l'espace vectoriel
F256n (cf. l'appendice A).
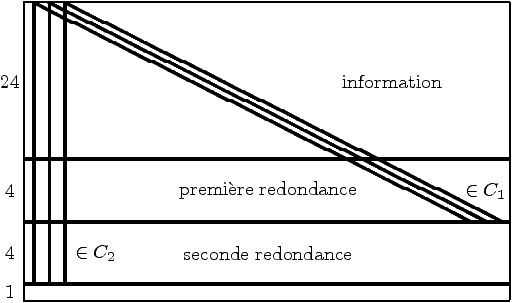
L'information musicale est découpée en bloc de 24 octets et placée
dans une table d'entrelacement de 24 lignes. La redondance permettant
la correction des erreurs est ajoutée en deux fois, la première fois
en diagonale à l'aide du code C1, la seconde fois verticalement à
l'aide du code C2. Un trente-troisième octet de service est ajouté
au bout de chaque colonne.
2.1 Codage
Les procédures de codage pour C1 et C2 se décrivent
mathématiquement de la façon suivante :
|
|
| F256k |
→ |
F256k+4 |
| (x1,…,xk) |
↦ |
(x1,…,xk,xk+1,xk+2,xk+3,xk+4) |
|
(xk+1,xk+2,xk+3,xk+4) = (x1,…,xk) R
où k vaudra 24 ou 28 respectivement pour les codes C1 et C2.
Dans les deux cas les quatres symboles supplémentaires dépendent
linéairement des k premiers. La matrice R est de taille k×
4 (et sera différente pour C1 et C2).
Le schéma de codage complet est le suivant :
-
l'information est découpée en blocs de 24 octets,
- chaque bloc est codé en un mot de C1,
- les mots de C1 sont placés dans une table d'entrelacement à
retard 4 (cf. appendice B),
- chaque colonne de la table est codée en un mot de C2,
- les données sont inscrites sur le disque colonne par colonne.
Le détail des procédures de codage de C1 et C2 n'est pas utile à
ce stade, elles seront explicitées sur la page web du projet.
2.2 Décodage
Les deux codes considérés ont une distance minimale 5, c'est-à-dire
qu'ils permettent de corriger jusqu'à 2 erreurs ou 4 effacements (cf.
l'appendice A).
La procédure de décodage est appliquée à la table d'entrelacement.
Nous avons successivement :
-
Un décodeur d'une erreur pour C2 qui agit de la façon
suivante sur chaque colonne y∈F25632 de la table
d'entrelacement :
-
s'il existe un mot x dans C1 tel que dH(x,y)≤ 1
alors l'éventuel symbole erroné est modifié,
- sinon tous les symboles de la colonne sont marqués comme
effacés.
- Un décodeur de quatre effacements pour C1 qui agit de la
façon suivante sur toute diagonale y∈F25628 de la table
d'entrelacement (tronquée aux 28 premières lignes) :
-
si moins de quatre symboles sont effacés, on cherche le seul
mot de C1 coincidant avec les symboles non effacés ; s'il
existe, on remplace les symboles effacés par les valeurs de ce
mot,
- si plus de quatre symboles sont effacés, ou si l'on n'a pas
trouvé de mot de C1, tous les symboles de la diagonale sont
marqués comme effacés.
Le détail des procédures de décodage de C1 et C2 n'est pas utile
à ce stade, elles seront explicitées sur la page web du projet.
3 Travail demandé
Il s'agit de programmer un démonstrateur qui incluera :
-
le codage,
- une modélisation des erreurs,
- le décodage.
Pour mettre en place la démonstration, l'utilisation de fichiers audio
n'est pas pertinente car il est difficile d'entendre les erreurs. En
revanche avec des fichiers d'image (typiquement au format ppm), il est
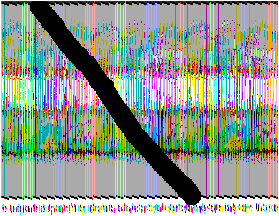
possible de percevoir les erreurs. Par exemple dans l'exemple
ci-dessous on voit l'effet d'une rayure (en bas à droite) sur un
fichier codé.
 |
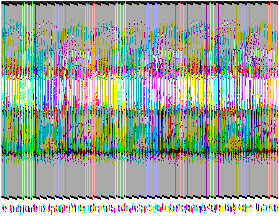 |
| Image originale |
Information après entrelacement |
| |
 |
 |
| Une rayure |
Effet de la rayure sur l'information |
3.1 Codage et décodage
À l'entête des fichiers près (qu'il faudra parser et adapter) il
s'agit du codage et du décodage décrit précédemment. Un fichier codé
sera plus gros que le fichier original. On pourra le manipuler comme
une image en rallongeant les lignes, par exemple :
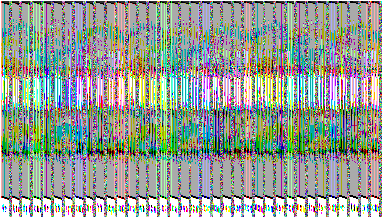 |
| Image entrelacée codée |
3.2 Modélisation des erreurs
Les erreurs se produiront dans le fichier codé et sont de deux types :
-
des erreurs isolées, qui affectent un seul octet et qui
correspondent à des imprécisions de lecture ou à des défaut sur le
plastique. Le taux de ces erreurs est très faible en général (moins
d'un octet sur mille), mais il pourra être intéressant de voir ce
qui se passe lorsqu'il augmente.
- des erreurs en rafales, qui affectent un grand nombre d'octets
consécutifs qui peu aller jusqu'à quelques centaines voire quelques
milliers.
Il y a deux approches possibles pour ajouter des erreurs au fichier
codé. La première consiste à écrire un programme spécialisé qui lira
le fichier, et, selon un modèle aléatoire qu'il faudra définir
précisement, le modifie. L'autre approche consiste à utiliser un
logiciel de traitement d'image (gimp par exemple) pour ajouter une ou
plusieurs rayures au fichier codé.
3.3 Première extension : interpolation
Il existe un second mécanisme de protection de l'information dans le
standard du CD audio, qui consiste à espacer au maximum les
échantillons musicaux (pour nous les pixels) consécutifs de façon à
pouvoir interpoler l'information manquante si un mot de code venait à
ne pas être décodé. Des informations complémentaires seront fournies
sur la page web.
3.4 Seconde extension : Analyse de la capacité de correction
Il s'agit d'une extension à géométrie variable. Une fois le
démonstrateur achevé, il peut être utilisé pour effectuer des
simulation d'erreurs et de correction pour divers modèle d'erreurs
significatifs. Il s'agit de faire varier le taux des erreurs isolées,
le nombre et la longueur des rafales, et d'étudier la qualité de
l'information corrigée en fonction de tous ces paramètres.
A Distance de Hamming et codes correcteurs
Soit F un corps fini et n un entier positif. La distance de Hamming sur Fn est définie entre deux mots
x=(x1,…,xn) et y=(y1,…,yn) de Fn par
:
|
dH(x,y) = |
| |
{i∣ 1≤ i≤ n, xi≠ yi} |
| |
.
|
Un code correcteur d'erreur linéaire de longueur n sur F
est un sous-espace métrique non vide de Fn muni de la
distance de Hamming. La dimension d'un code linéaire est sa dimension
en tant que sous-espace vectoriel de Fn, elle est
traditionnellement notée k. Nous parlerons de code (n,k), bien sûr
k≤ n.
La distance minimale d'un code est la plus petite distance entre
deux mots distincts du code. Il s'agit d'un paramètre important
puisque qu'elle fixe la capacité de correction d'un code.
Proposition 1
Un code correcteur de distance minimale d peut corriger jusqu'à
(d-1)/2 erreurs.
Autrement dit si x est un mot de code et si y vérifie
dH(x,y)≤(d-1)/2, alors il n'existe pas d'autre mot de code plus
proche de y pour la distance de Hamming.
Correction d'effacement.
Lorsqu'un symbole dans un mot est
erroné mais que sa position est connue, on parle d'effacement. Il
s'agit d'une situation plus favorable en terme de capacité de
correction.
Proposition 2
Un code correcteur de distance minimale d peut corriger jusqu'à
d-1 effacements.
En effet, si d-1 positions d'un mot de code x sont effacées, il
n'existe aucun autre mot de code qui coincide sur les n-d+1
positions restantes.
B Entrelacement à retard
L'entrelacement est une technique classique en télécommunication
consistant à mélanger l'information avant de la transmettre. Dans le
standard du disque compact il s'agit d'un entrelacement à
retard. Par exemple, pour entrelacer 20 symboles, de x1 à
x20, avec une profondeur 4 (taille des blocs) et un retard 1, on
remplit une table d'entrelacement en diagonale de la façon suivante :
| x1 |
x5 |
x9 |
x13 |
x17 |
∙ |
∙ |
∙ |
| ∙ |
x2 |
x6 |
x10 |
x14 |
x18 |
∙ |
∙ |
| ∙ |
∙ |
x3 |
x7 |
x11 |
x15 |
x19 |
∙ |
| ∙ |
∙ |
∙ |
x4 |
x8 |
x12 |
x16 |
x20 |
L'ordre après entrelacement sera :
x1, ∙, ∙, ∙, x5, x2, ∙, ∙,
x9, x6, x3, ∙, x13, x10, x7, x4, x17,
x14, x11, x8, ∙, x18, x15, x12, ∙,
∙, x19, x16, ∙, ∙, ∙, x20
Remarques :
-
Il faut remplir avec des valeurs arbitraires (∙) le
début et la fin de la table.
- La table peut contenir un nombre d'élément égal à n'importe quel
multiple de la profondeur de l'entrelacement. Ce multiple n'a pas
besoin d'être connu à l'avance.
On peut augmenter le retard en changeant la pente de la diagonale. Par
exemple un retard 2 signifie que le début de la table serait :
| x1 |
x5 |
x9 |
x13 |
x17 |
⋯ |
| ∙ |
∙ |
x2 |
x6 |
x10 |
⋯ |
| ∙ |
∙ |
∙ |
∙ |
x3 |
⋯ |
| ∙ |
∙ |
∙ |
∙ |
∙ |
⋯ |
La table d'entrelacement du disque compact est à retard 4 (x2 est
sur la deuxième ligne de la cinquième colonne).
Ce document a été traduit de LATEX par
HEVEA.