Chapitre 8 Exploration
Dans ce chapitre, on recherche des algorithmes pour rťsoudre des
problŤmes se prťsentant sous la forme suivante:
On se donne un ensemble E fini et ŗ chaque ťlťment e de E est
affectťe une valeur v(e) (en gťnťral, un entier positif), on se
donne de plus un prťdicat (une fonction ŗ valeurs {vrai,
faux}) C sur l'ensemble des parties de E. Le problŤme consiste
ŗ construire un sous ensemble F de E tel que:
- C(F) est satisfait
- Se ő Fv(e) soit maximal
(ou minimal, dans certains cas)
Les mťthodes dťveloppťes pour rťsoudre ces problŤmes sont de
natures trŤs diverses. Pour certains exemples, il existe un algorithme
trŤs simple consistant ŗ initialiser F par F= ō, puis ŗ
ajouter successivement des ťlťments suivant un certain critŤre,
jusqu'ŗ obtenir la solution optimale, c'est ce qu'on appelle l'algorithme glouton. Tous les problŤmes ne sont pas rťsolubles
par l'algorithme glouton mais, dans le cas oý il s'applique, il est
trŤs efficace. Pour d'autres problŤmes, c'est un algorithme
dit de programmation dynamique qui permet d'obtenir la solution,
il s'agit alors d'utiliser certaines particularitťs de la solution
qui permettent de diviser le problŤme en deux; puis de rťsoudre
sťparťment chacun des deux sous-problŤmes, tout en conservant en
table certaines informations intermťdiaires. Cette technique, bien
que moins efficace que l'algorithme glouton, donne quand mÍme un
rťsultat intťressant car l'algorithme mis en oeuvre est en gťnťral
polynomial. Enfin, dans certains cas, aucune des deux mťthodes
prťcťdentes ne donne de rťsultat et il faut alors utiliser des
procťdures d'exploration systťmatique de l'ensemble de toutes les
parties de E satisfaisant C, cette exploration systťmatique est
souvent appelťe exploration arborescente (ou backtracking en anglais).
8.1 Algorithme glouton
Comme il a ťtť dit, cet algorithme donne trŤs rapidement un
rťsultat. En revanche ce rťsultat n'est pas toujours la solution
optimale. L'affectation d'une ou plusieurs ressource ŗ des
utilisateurs (clients, processeurs, etc.) constitue une classe
importante de problŤmes. Il s'agit de satisfaire au mieux certaines
demandes d'accŤs ŗ une ou plusieurs ressources, pendant une durťe
donnťe, ou pendant une pťriode de temps dťfinie prťcisťment. Le
cas le plus simple de ces problŤmes est celui d'une seule ressource,
pour laquelle sont faites des demandes d'accŤs ŗ des pťriodes
dťterminťes. Nous allons montrer que dans ce cas trŤs simple,
l'algorithme glouton s'applique. Dans des cas plus complexes,
l'algorithme donne une solution approchťe, dont on se contente
souvent, vu le temps de calcul prohibitif de la recherche de l'optimum
exact.
8.1.1 Affectation d'une ressource
Le problŤme dťcrit prťcisťment ci-dessous peut Ítre rťsolu par
l'algorithme glouton (mais, comme on le verra, l'algorithme glouton ne
donne pas la solution optimale pour une autre formulation du
problŤme, pourtant proche de celle-ci). Il s'agit d'affecter une
ressource unique, non partageable, successivement ŗ un certain nombre
d'utilisateurs qui en font la demande en prťcisant la pťriode exacte
pendant laquelle ils souhaitent en disposer.
On peut matťrialiser ceci en prenant pour illustration la location
d'une seule voiture. Des clients formulent un ensemble de demandes de
location et, pour chaque demande sont donnťs le jour du dťbut de la
location et le jour de restitution du vťhicule, le but est d'affecter
le vťhicule de faÁon ŗ satisfaire le maximum de clients (et non
pas de maximiser la somme des durťes de location). On peut formuler
ce problŤme en utilisant le cadre gťnťral considťrť plus haut.
L'ensemble E est celui des demandes de location, pour chaque
ťlťment e de E, on note d(e) la date du dťbut de la location
et f(e) > d(e) la date de fin. La valeur v(e) de tout ťlťment
e de E est ťgale ŗ 1 et la contrainte ŗ respecter pour le
sous ensemble F ŗ construire est la suivante:
" e1,e2 ő F d(e1) £ d(e2)
ř f(e1) £ d(e2)
puisque, disposant d'un seul vťhicule, on ne peut le louer
qu'ŗ un seul client ŗ la fois. L'algorithme glouton s'exprime comme
suit:
- Etape 1: Classer les ťlťments de E par ordre des dates
de fins croissantes. Les ťlťments de E constituent alors une suite
e1, e2, ... en telle que f(e1) £ f(e2), ... £
f(en)
- Initialiser F := ō
- Etape 2: Pour i variant de 1 ŗ n, ajouter la
demande ei ŗ F si celle-ci ne chevauche pas la derniŤre
demande appartenant ŗ F.
Montrons que l'on a bien obtenu ainsi la solution optimale.
Soit F = {x1, x2, ... xp} la solution obtenue par
l'algorithme glouton et soit G = {y1, y2, ... yq}, q ≥ p
une solution optimale. Dans les deux cas nous supposons que les
demandes sont classťes par dates de fins croissantes. Nous allons
montrer que p=q. Supposons que " i <k, on ait xi = yi et
que k soit le plus petit entier tel que xk Ļ yk, alors par
construction de F on a: f(yk) ≥ f(xk). On peut alors
remplacer G par G' = {y1, y2, ... yk-1, xk,yk+1,
yq} tout en satisfaisant ŗ la contrainte de non chevauchement des
demandes, ainsi G' est une solution optimale ayant plus d'ťlťments
en commun avec F que n'en avait G. En rťpťtant cette opťration
suffisamment de fois on trouve un ensemble H de mÍme cardinalitť
que G et qui contient F. L'ensemble H ne peut contenir d'autres
ťlťments car ceux-ci auraient ťtť ajoutťs ŗ F par l'algorithme
glouton, ceci montre bien que p=q.
Remarques
1. Noter que le choix de classer les demandes par
dates de fin croissantes est important. Si on les avait classťes, par
exemple, par dates de dťbut croissantes, on n'aurait pas obtenu le
rťsultat. On le voit sur l'exemple suivant avec trois demandes e1,
e2, e3 dont les dates de dťbut et de fin sont donnťes par le
tableau suivant:
Bien entendu, pour des raisons ťvidentes de symťtrie, le classement
par dates de dťbut dťcroissantes donne aussi le rťsultat optimal.
2. On peut noter aussi que si le but est de maximiser
la durťe totale de location du vťhicule l'algorithme glouton ne
donne pas l'optimum. En particulier, il ne considťrera pas comme
prioritaire une demande de location de durťe trŤs importante.
L'idťe est alors de classer les demandes par durťes dťcroissantes
et d'appliquer l'algorithme glouton, malheureusement cette technique
ne donne pas non plus le bon rťsultat (il suffit de considťrer une
demande de location de 3 jours et deux demandes qui ne se chevauchent
pas mais qui sont incompatibles avec la premiŤre chacune de durťe
ťgale ŗ 2 jours). De fait, le problŤme de la maximisation de cette
durťe totale est NP complet, il est donc illusoire de penser trouver
un algorithme simple et efficace.
3. S'il y a plus d'une ressource ŗ affecter, par
exemple deux voitures ŗ louer, l'algorithme glouton consistant ŗ
classer les demandes suivant les dates de fin et ŗ affecter la
premiŤre ressource disponible, ne donne pas l'optimum.
8.1.2 Arbre recouvrant de poids minimal
Un exemple classique d'utilisation de l'algorithme glouton est la
recherche d'un arbre recouvrant de poids minimal dans un graphe
symťtrique, il prend dans ce cas particulier le nom d'algorithme de
Kruskal. Dťcrivons briŤvement le problŤme et l'algorithme.
Un graphe symťtrique est donnť par un ensemble X de sommets
et un ensemble A d'arcs tel que, pour tout a ő A, il existe un
arc opposť a' dont l'origine est l'extrťmitť de a et dont
l'extrťmitť est l'origine de a. Le couple {a, a'} forme
une arÍte. Un arbre est un graphe symťtrique tel que
tout couple de sommets est reliť par un chemin (connexitť) et qui ne
possŤde pas de circuit (autres que ceux formťs par un arc et son
opposť). Pour un graphe symťtrique G= (X,A) quelconque, un arbre
recouvrant est donnť par un sous ensemble de l'ensemble des arÍtes
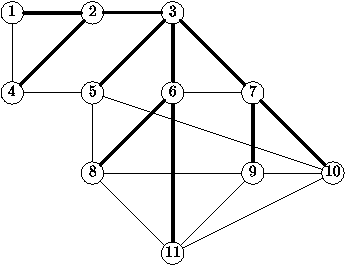
qui forme un arbre ayant X pour ensemble de sommets (voir figure
8.1). Pour possťder un arbre recouvrant, un
graphe doit Ítre connexe. Dans ce cas, les arborescences construites
par les algorithmes dťcrits au chapitre 5 sont des arbres
recouvrants. Lorsque chaque arÍte du graphe est affectťe d'un
certain poids, se pose le problŤme de la recherche d'un arbre
recouvrant de poids minimal (c'est ŗ dire un arbre dont la somme des
poids des arÍtes soit minimale). Une illustration de ce problŤme est
la rťalisation d'un rťseau ťlectrique ou informatique entre
diffťrents points, deux points quelconques doivent toujours Ítre
reliťs entre eux (connexitť) et on doit minimiser le coŻt de la
rťalisation. Le poids d'une arÍte est, dans ce contexte, le coŻt
de construction de la portion du rťseau reliant ses deux
extrťmitťs.
Figure 8.1 : Un graphe symťtrique et l'un de ses arbres recouvrants
On peut facilement formuler le problŤme dans le cadre gťnťral
donnť en dťbut de chapitre: E est l'ensemble des arÍtes du
graphe, la condition C ŗ satisfaire par F est de former un graphe
connexe, enfin il faut minimiser la somme des poids des ťlťments de
F. Ce problŤme peut Ítre rťsolu trŤs efficacement par
l'algorithme glouton suivant :
On montre que l'algorithme glouton donne l'arbre de poids minimal en
utilisant la propriťtť suivante des arbres recouvrants d'un graphe:
Soient T et U deux arbres recouvrants distincts d'un graphe G et
soit a une arÍte de U qui n'est pas dans T. Alors il existe une
arÍte b de T telle que U \ {a }» {b } soit
aussi un arbre recouvrant de G.
Plus gťnťralement on montre que l'algorithme glouton donne le
rťsultat si et seulement si la propriťtť suivante est vťrifiťe
par les sous ensembles F de E satisfaisant C:
Si F et G sont deux ensembles qui satisfont la condition C et si
x est un ťlťment qui est dans F et qui n'est pas dans G, alors
il existe un ťlťment de G tel que F \ {x}» {y }
satisfasse C.
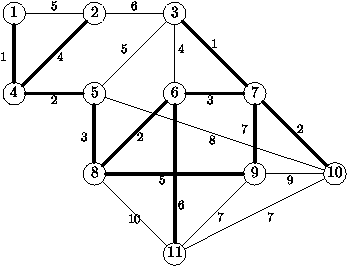
Un exemple d'arbre recouvrant de poids minimal est donnť
sur la figure 8.2.
Figure 8.2 : Un arbre recouvrant de poids minimum
8.2 Exploration arborescente
De trŤs nombreux problŤmes d'optimisation ou de recherche de
configurations particuliŤres donnent lieu ŗ un algorithme qui
consiste ŗ faire une recherche exhaustive des solutions. Ces
algorithmes paraissent simples puisqu'il s'agit de parcourir
systťmatiquement un ensemble de solutions, mais bien que leur
principe ne soit pas particuliŤrement ingťnieux, la programmation
nťcessite un certain soin.
8.2.1 Sac ŗ dos
Prenons pour premier exemple le problŤme dit du sac ŗ dos;
soit un ensemble E d'objets chacun ayant un certain poids, un entier
positif notť p(e), et soit M un rťel qui reprťsente la charge
maximum que l'on peut emporter dans un sac ŗ dos. La question est de
trouver un ensemble d'objets dont la somme des poids soit la plus
voisine possible de M tout en lui ťtant infťrieure ou ťgale. Le
problŤme est ici formulť dans les termes gťnťraux du dťbut du
chapitre, la condition C portant sur le poids du sac ŗ ne pas
dťpasser.
Il est assez facile de trouver des exemples pour lesquels l'algorithme
glouton ne donne pas le bon rťsultat, il suffit en effet de
considťrer 4 objets de poids respectifs 4,3,3,1 pour remplir un
sac de charge maximum ťgale ŗ 6. On s'apperÁoit que si l'on
remplit le sac en prťsentant les objets en ordre de poids
dťcroissants et en retenant ceux qui ne font pas dťpasser la
capacitť maximale, on obtiendra une charge ťgale ŗ 5. Si ŗ
l'opposť, on classe les objets par ordre de poids croissants, et que
l'on applique l'algorithme glouton, la charge obtenue sera ťgale ŗ
4, alors qu'il est possible de remplir le sac avec deux objets de
poids 3 et d'obtenir l'optimum.
Le problŤme du sac ŗ dos, lorsque la capacitť du sac n'est pas un
entier, 1
est un
exemple typique classique de problŤme (NP-complet) pour lequel aucun
algorithme efficace n'est connu et oý il faut explorer toutes les
possibilitťs pour obtenir la meilleure solution. Une bonne
programmation de cette exploration systťmatique consiste ŗ utiliser la
rťcursivitť. Notons n le nombre d'ťlťments de E, nous utiliserons
un tableau sac permettant de coder toutes les
possibilitťs, un objet i est mis dans le sac si sac[i] = true,
il n'est pas mis si sac[i] = false. Il faut donc parcourir tous
les vecteurs possibles de boolťens, pour cela on considŤre
successivement toutes les positions i= 1, ... n et on effectue
les deux choix possibles pour sac[i] en ne choisissant pas la
derniŤre possibilitť si l'on dťpasse la capacitť du sac. On utilise un
entier meilleur qui mťmorise la plus petite valeur trouvťe pour
la diffťrence entre la capacitť du sac et la somme des poids des
objets qui s'y trouvent. Un tableau msac garde en mťmoire le
contenu du sac qui rťalise ce minimum. La procťdure rťcursive calcul(i,u) a pour paramŤtres d'appel, i l'objet pour lequel on
doit prendre une dťcision, et u la capacitť disponible
restante. Elle considŤre deux possibilitťs pour l'objet i l'une
pour laquelle il est mis dans le sac (si on ne dťpasse pas la capacitť
restante u), l'autre pour laquelle il n'y est pas mis. La
procťdure appelle calcul(i+1, u) et calcul(i+1, u -
p[i]). Ainsi le premier appel de calcul(i, u) est fait avec
i = 0 et u ťgal ŗ la capacitť M du sac, les appels
successifs feront ensuite augmenter i (et diminuer u)
jusqu'ŗ atteindre la valeur n. Le rťsultat est mťmorisť s'il
amťliore la valeur courante de meilleur.
static void calcul (int i, float u) {
if (i >= n) {
if (u < meilleur) {
for (int j = 0; i < n; ++i)
msac[i] = sac[i];
meilleur = u;
}
} else {
if (p[i] <= u) {
sac[i] = true;
calcul(i + 1, u - p[i]);
}
sac[i] = false;
calcul(i + 1, u);
}
}
On vťrifie sur des exemples que cette procťdure donne des rťsultats
assez rapidement pour n £ 20. Pour des valeurs plus grandes le
temps mis est bien plus long car il croÓt comme 2n.
8.2.2 Placement de reines sur un ťchiquier
Le placement de reines sur un ťchiquier sans qu'aucune d'entre elles
ne soit en prise par une autre constitue un autre exemple de recherche
arborescente. Lŗ encore il faut parcourir l'ensemble des solutions
possibles. Pour les valeurs successives de i, on place une reine
sur la ligne i et sur une colonne j = pos[i] en vťrifiant bien
qu'elle n'est pas en prise. Le tableau pos que l'on remplit
rťcursivement contient les positions des reines dťjŗ placťes.
Tester si deux reines sont en conflit est relativement simple. Notons
i1,j1 et i2, j2 leurs positions respectives (ligne et colonne)
il y a conflit si i1 = i2 (elles sont alors sur la mÍme ligne),
ou si j1 = j2 (mÍme colonne) ou si |i1 - i2 | = |j1 -j2|
(mÍme diagonale).
static boolean conflit (int i1, int j1, int i2, int j2) {
return (i1 == i2) || (j1 == j2) ||
(Math.abs (i1 - i2) == Math.abs (j1 - j2));
}
Celle-ci peut Ítre appelťe plusieurs fois pour tester si
une reine en position i, j est compatible avec les
reines prťcťdemment placťes sur les lignes 1, ..., i - 1:
static boolean compatible (int i, int j) {
for (int k = 0; k < i; ++k)
if (conflit (i, j, k, pos[k]))
return false;
return true;
}
Figure 8.3 : Huit reines sur un ťchiquier
La fonction rťcursive qui trouve une solution au problŤme
des reines est alors la suivante:
static void reines (int i) {
if (i >= nbReines)
imprimerSolution();
else {
for (int j = 0; j < nbReines; ++j)
if compatible (i, j) {
pos[i] = j;
reines (i+1);
}
}
}
La boucle for ŗ l'intťrieur de la procťdure permet de parcourir
toutes les positions sur la ligne i compatibles avec les reines
dťjŗ placťes. Les appels successifs de Reines(i) modifient la
valeur de pos[i] dťterminťe par l'appel prťcťdent. La procťdure
prťcťdente affiche toutes les solutions possibles, il est assez facile
de modifier la procťdure en s'arrÍtant dŤs que l'on a trouvť une
solution ou pour simplement compter le nombre de solutions
diffťrentes. En lanÁant Reines(0), on trouve ainsi 90
solutions pour un ťchiquier 8 ◊ 8 dont l'une d'elles est donnťe
figure 8.3.
Remarque
Dans les deux exemples donnťs plus haut,
toute la difficultť rťside dans le parcours de toutes les solutions
possibles, sans en oublier et sans revenir plusieurs fois sur la
mÍme. On peut noter que l'ensemble de ces solutions peut Ítre vu
comme les sommets d'une arborescence qu'il faut parcourir. La
diffťrence avec les algorithmes dťcrits au chapitre 5 est que l'on
ne reprťsente pas cette arborescence en totalitť en mťmoire mais
simplement la partie sur laquelle on se trouve.
8.3 Programmation dynamique
Pour illustrer la technique d'exploration appelťe programmation
dynamique, le mieux est de commencer par un exemple. Nous considťrons
ainsi la recherche de chemins de longueur minimale entre tous les
couples de points d'un graphe aux arcs valuťs.
8.3.1 Plus courts chemins dans un graphe
Dans la suite, on considŤre un graphe G= (X,A) ayant X comme
ensemble de sommets et A comme ensemble d'arcs. On se donne une
application l de A dans l'ensemble des entiers naturels, l(a)
est la longueur de l'arc a. La longueur d'un chemin est ťgale
ŗ la somme des longueurs des arcs qui le composent. Le problŤme
consiste ŗ dťterminer pour chaque couple (xi, xj) de sommets, le
plus court chemin, s'il existe, qui joint xi ŗ xj. Nous
commenÁons par donner un algorithme qui dťtermine les longueurs
des plus courts chemins notťes d(xi, xj); on convient de
noter d(xi, xj)= • s'il n'existe pas de chemin entre
xi et xj (en fait il suffit dans la suite de remplacer •
par un nombre suffisamment grand par exemple la somme des longueurs de
tous les arcs du graphe). La construction effective des chemins sera
examinťe ensuite. On suppose qu'entre deux sommets il y a au plus un
arc. En effet, s'il en existe plusieurs, il suffit de ne retenir que
le plus court.
Les algorithmes de recherche de chemins les plus courts
reposent sur l'observation trŤs simple mais importante suivante:
Remarque
Si f est un chemin de longueur
minimale joignant x ŗ y et qui passe par z, alors il se
dťcompose en deux chemins de longueur minimale l'un qui joint x ŗ
z et l'autre qui joint z ŗ y.
Dans la suite, on suppose les sommets numťrotťs x1, x2,
... xn et, pour tout k>0 on considŤre la propriťtť Pk
suivante pour un chemin:
(Pk(f)) Tous les sommets de f, autres que son
origine et son
extrťmitť, ont un indice strictement infťrieur ŗ k.
On peut remarquer qu'un chemin vťrifie P1 si et
seulement s'il se compose d'un unique arc, d'autre part la condition
Pn+1 est satisfaite par tous les chemins du graphe. Notons
dk (xi,xj) la longueur du plus court chemin qui vťrifie
Pk et qui a pour origine xi et pour extrťmitť xj. Cette
valeur est • si aucun tel chemin n'existe. Ainsi
d1(xi,xj)= • s'il n'y a pas d'arc entre xi et xj
et vaut l(a) si a est cet arc. D'autre part dn+1 =
d. Le lemme suivant permet de calculer les dk+1
connaissant les dk (xi,xj). On en dťduira un algorithme
itťratif.
Lemme
Les relations suivantes sont satisfaites par les
dk:
dk+1(xi, xj) = min(dk(xi,xj), dk(xi,xk)
+dk(xk,xj))
Preuve
Soit un chemin de longueur minimale
satisfaisant Pk+1, ou bien il ne passe pas par xk et on a
dk+1(xi, xj) = dk(xi,xj)
ou bien il passe par xk et, d'aprŤs la remarque prťliminaire, il
est composť d'un chemin de longueur minimale joignant xi ŗ xk
et satisfaisant Pk et d'un autre minimal aussi joignant xk ŗ
xj. Il a donc pour longueur: dk(xi,xk)
+dk(xk,xj).
L'algorithme suivant pour la recherche du plus court chemin met ŗ
jour une matrice delta[i,j] qui a ťtť initialisťe par les
longueurs des arcs et par un entier suffisamment grand s'il n'y a pas
d'arc entre xi et xj. A chaque itťration de la boucle externe,
on fait croÓtre l'indice k du dk calculť.
for (k = 0; k < n; ++k)
for (i = 0; i < n; ++i)
for (j = 1; j < n; ++j)
delta[i][j] = Math.min(delta[i][j], delta[i][k] + delta[k][j]);
On note la similitude avec l'algorithme de recherche de la fermeture
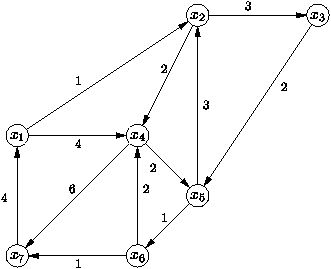
transitive d'un graphe exposť au chapitre 5. Sur l'exemple du graphe
donnť sur la figure 8.4, on part de la matrice
d1 donnťe par
| d1=
|
ś
Á
Á
Á
Á
Á
Á
Á
Ť
|
|
| 0 | 1 | • | 4 | • | • | • |
| • | 0 | 3 | 2 | • | • | • |
| • | • | 0 | • | 2 | • | • |
| • | • | • | 0 | 2 | • | 6 |
| • | 3 | • | • | 0 | 1 | • |
| • | • | • | 2 | • | 0 | 1 |
| 4 | • | • | • | • | • | 0
| |
|
Ų
ų
ų
ų
ų
ų
ų
ų
Ý
|
Figure 8.4 : Un graphe aux arcs valuťs
AprŤs le calcul on obtient:
| d =
|
ś
Á
Á
Á
Á
Á
Á
Á
Ť
|
|
| 0 | 1 | 4 | 3 | 5 | 6 | 7 |
| 10 | 0 | 3 | 2 | 4 | 5 | 6 |
| 8 | 5 | 0 | 5 | 2 | 3 | 4 |
| 8 | 5 | 8 | 0 | 2 | 3 | 4 |
| 6 | 3 | 6 | 3 | 0 | 1 | 2 |
| 5 | 6 | 9 | 2 | 4 | 0 | 1 |
| 4 | 5 | 8 | 7 | 9 | 10 | 0
| |
|
Ų
ų
ų
ų
ų
ų
ų
ų
Ý
|
Pour le calcul effectif des chemins les plus courts, on utilise une
matrice qui contient Suiv[i,j], le sommet qui suit i dans le
chemin le plus court qui va de i ŗ j. Les valeurs Suiv[i,j]
sont initialisťes ŗ j s'il existe un arc de i vers j et ŗ
-1 sinon, Suiv[i,i] est lui initialisť ŗ i. Le calcul
prťcťdent qui a donnť d peut s'accompagner de celui de
Suiv en procťdant comme suit:
for (int k = 0; k < n; ++k)
for (int i = 0; i < n; ++i)
for (int j = 0; j < n; ++j)
if (delta[i][j] > (delta[i][k] + delta[k][j]) {
delta[i][j] = delta[i][k] + delta[k][j];
suivant[i][j] = suivant[i][k];
}
Une fois le calcul des deux matrices effectuť on peut retrouver le
chemin le plus court qui joint i ŗ j par la procťdure:
static void plusCourtChemin(int i, int j) {
for (int k = i; k != j; k = suivant[k][j])
System.out.print (k + " ");
System.out.println (j);
}
Sur l'exemple prťcťdent on trouve:
| Suiv =
|
ś
Á
Á
Á
Á
Á
Á
Á
Ť
|
|
| 1 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4 | 2 | 3 | 4 | 4 | 4 | 4 |
| 5 | 5 | 3 | 5 | 5 | 5 | 5 |
| 5 | 5 | 5 | 4 | 5 | 5 | 5 |
| 6 | 2 | 2 | 6 | 5 | 6 | 6 |
| 7 | 7 | 7 | 4 | 4 | 6 | 7 |
| 1 | 1 | 1 | 1 | 1 | 1 | 7
| |
|
Ų
ų
ų
ų
ų
ų
ų
ų
Ý
|
8.3.2 Sous-sťquences communes
On utilise aussi un algorithme de programmation dynamique pour
rechercher des sous-sťquences communes ŗ deux sťquences donnťes.
prťcisons tout d'abord quelques dťfinitions.
Une sťquence (ou un mot) est une suite finie de
symboles (ou lettres) pris dans un ensemble fini (ou alphabet). Si u=a1∑∑∑ an est une sťquence, oý
a1,... ,an sont des lettres, l'entier n est la longueur
de u. Une sťquence v=b1∑∑∑ bm est une sous-sťquence de u=a1∑∑∑ an s'il existe des entiers
i1,... ,im, (1£ i1<∑∑∑ im£ n) tels que aik=bk
(1£ k£ m). Une sťquence w est une sous-sťquence
commune aux sťquences u et v si w est sous-sťquence de
u et de v. Une sous-sťquence commune est maximale si
elle est de longueur maximale.
On cherche ŗ dťterminer la longueur d'une sous-sťquence
commune maximale ŗ u=a1∑∑∑ an et v=b1∑∑∑ bm. Pour
cela, on note L(i,j) la longueur d'une sous-sťquence commune
maximale aux mots a1∑∑∑ ai et b1∑∑∑ bj, (0£ j£ m,
0£ i£ n). On peut montrer que
| L(i,j)= |
ž
Ū
Ó
|
| 1 + L(i-1,j-1) | si ai=bj |
|
max (L(i,j-1),L(i-1,j)) | sinon. | | (*) |
En effet, soit w une sous sťquence de longueur maximale, commune
ŗ a1∑∑∑ ai-1 et ŗ b1∑∑∑ bj-1 si ai = bj,
wai est une sous-sťquence commune maximale ŗ a1∑∑∑ ai et
b1∑∑∑ bj. Si ai Ļ bj alors une sous-sťquence commune ŗ
a1∑∑∑ ai et b1∑∑∑ bj est ou bien commune ŗ a1∑∑∑
ai et b1∑∑∑ bj-1 (si elle ne se termine pas par bj); ou
bien ŗ a1∑∑∑ ai-1 et b1∑∑∑ bj, (si elle ne se termine
par ai). On obtient ainsi l'algorithme qui permet de dťterminer
la longueur d'une sous sťquence commune maximale ŗ a1∑∑∑ an
et b1∑∑∑ bm
static void longueurSSC (String u, String v) {
int n = u.length();
int m = v.length();
int longueur[][] = new int[n][m];
for (int i = 0; i < n; ++i) longueur[i, 0] = 0;
for (int j = 0; j < m; ++j) longueur[0, j] = 0;
for (int i = 1; i < n; ++i)
for (int j = 1; j < m; ++j)
if (u.charAt(i) == v.charAt(j))
longueur[i][j] = 1 + longueur[i-1][j-1];
else if longueur[i][j-1] > longueur[i-1][j]
longueur[i][j] = longueur[i][j-1];
else
longueur[i][j] = longueur[i-1][j];
}
Il est assez facile de transformer l'algorithme pour retrouver une
sous-sťquence maximale commune au lieu de simplement calculer sa
longueur. Pour cela, on met ŗ jour un tableau provient qui
indique lequel des trois cas a permis d'obtenir la longueur maximale.
static void longueurSSC (String u, String v,
int[][] longueur, int[][] provient) {
int n = u.length();
int m = v.length();
for (int i = 0; i < n; ++i) longueur[i, 0] = 0;
for (int j = 0; j < m; ++j) longueur[0, j] = 0;
for (int i = 1; i < n; ++i)
for (int j = 1; j < m; ++j)
if (u.charAt(i) == v.charAt(j)) {
longueur[i][j] = 1 + longueur[i-1][j-1];
provient[i,j] = 1;
} else if longueur[i][j-1] > longueur[i-1][j] {
longueur[i][j] = longueur[i][j-1];
provient[i,j] = 2;
} else {
longueur[i][j] = longueur[i-1][j];
provient[i,j] = 3
}
}
Une fois ce calcul effectuť il suffit de remonter ŗ chaque
ťtape de i,j vers i-1, j-1, vers i, j-1 ou vers
i-1,j en se servant de la valeur de provient[i,j].
static String ssc (String u, String v) {
int n = u.length();
int m = v.length();
int longueur[][] = new int[n][m];
int provient[][] = new int[n][m];
longueurSSC (u, v, longueur, provient);
int lg = longueur[n][m];
StringBuffer res = new StringBuffer(lg);
int i = n, j = m;
for (int k = lg-1; k >= 0; )
switch (provient[i][j]) {
case 1: res.setCharAt(k, u.charAt(i-1)); --i; --j; --k;
break;
case 2: --j; break;
case 3: --i; break;
}
return new String(res);
}
Remarque
La recherche de sous-sťquences communes ŗ
deux sťquences intervient parmi les nombreux problŤmes
algorithmiques posťs par la recherche des propriťtťs des sťquences
reprťsentant le gťnome humain.
8.4 Programmes en Caml
(* les n reines, voir page X *)
let nReines n =
let pos = make_vect n 0 in
let conflit i1 j1 i2 j2 =
i1 = i2 || j1 = j2 ||
abs(i1 - i2) = abs (j1 - j2) in
let compatible i j =
try
for k = 0 to i-1 do
if conflit i j k pos.(k) then
raise Exit
done;
true
with Exit -> false in
let rec reines i =
if i >= n then
imprimerSolution pos
else
for j = 0 to n-1 do
if compatible i j then begin
pos.(i) <- j;
reines (i+1);
end
done in
reines 0;;
(* les n reines (suite) *)
#open "printf";;
let imprimerSolution pos =
let n = vect_length(pos) in
for i = 0 to n-1 do
for j = 0 to n-1 do
if j = pos.(i) then
printf "* "
else
printf " "
done;
printf "\n";
done;
printf "----------------------\n";;
(* les sous sťquences communes *)
let longueur_ssc u v =
let n = string_length u and
m = string_length v in
let longueur = make_matrix (n+1) (m+1) 0 and
provient = make_matrix (n+1) (m+1) 0 in
for i=1 to n do
for j=1 to m do
if u.[i-1] = v.[j-1] then begin
longueur.(i).(j) <- 1 + longueur.(i-1).(j-1);
provient.(i).(j) <- 1;
end else
if longueur.(i).(j-1) > longueur.(i-1).(j) then begin
longueur.(i).(j) <- longueur.(i).(j-1);
provient.(i).(j) <- 2;
end else begin
longueur.(i).(j) <- longueur.(i-1).(j);
provient.(i).(j) <- 3;
end
done
done;
longueur, provient;;
let ssc u v =
let n = string_length u and
m = string_length v in
let longueur, provient = longueur_ssc u v in
let lg = longueur.(n).(m) in
let res = create_string lg and
i = ref n and
j = ref m and
k = ref (lg-1) in
while !k >= 0 do
match provient.(!i).(!j) with
1 -> res.[!k] <- u.[!i-1]; decr i; decr j; decr k
| 2 -> decr j
| _ -> decr i
done;
res;;
- 1
- Dans le cas oý M est en entier, on peut trouver un
algorithme trŤs efficace fondť sur la programmation dynamique.