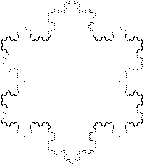Chapitre 2 Rťcursivitť
Les dťfinitions par rťcurrence sont assez courantes en
mathťmatiques. Prenons le cas de la suite de Fibonacci, dťfinie par
u0 = u1 = 1
un = un-1 + un-2 pour n > 1
On obtient donc la suite 1, 1, 2, 3, 5, 8, 13, 21, 34, 55,
89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,...Nous
allons voir que ces dťfinitions s'implťmentent trŤs simplement en
informatique par les dťfinitions rťcursives.
2.1 Fonctions rťcursives
2.1.1 Fonctions numťriques
Pour calculer la suite de Fibonacci, une transcription littťrale de la
formule est la suivante:
static int fib (int n) {
if (n <= 1)
return 1;
else
return fib (n-1) + fib (n-2);
}
fib est une fonction qui utilise son propre nom
dans la dťfinition d'elle-mÍme. Ainsi, si l'argument n
est plus petit que 1, on retourne comme valeur 1. Sinon, le rťsultat
est fib(n-1) + fib(n-2). Il est donc
possible en Java, comme en beaucoup d'autres langages (sauf
Fortran), de dťfinir de telles fonctions rťcursives.
D'ailleurs, toute suite Š un Ů dťfinie par rťcurrence
s'ťcrit de cette maniŤre en Java, comme le confirment les exemples
numťriques suivants: factorielle et le triangle de Pascal.
static int fact(int n) {
if (n <= 1)
return 1;
else
return n * fact (n-1);
}
static int C(int n, int p) {
if ((n == 0) || (p == n))
return 1;
else
return C(n-1, p-1) + C(n-1, p);
}
On peut se demander comment Java s'y prend
pour faire le calcul des fonctions rťcursives. Nous allons essayer de
le suivre sur le calcul de fib(4). Rappelons nous que les
arguments sont transmis par valeur dans le cas prťsent, et donc qu'un
appel de fonction consiste ŗ ťvaluer l'argument, puis ŗ se lancer
dans l'exťcution de la fonction avec la valeur de l'argument. Donc
fib(4) -> fib (3) + fib (2)
-> (fib (2) + fib (1)) + fib (2)
-> ((fib (1) + fib (1)) + fib (1)) + fib(2)
-> ((1 + fib(1)) + fib (1)) + fib(2)
-> ((1 + 1) + fib (1)) + fib(2)
-> (2 + fib(1)) + fib(2)
-> (2 + 1) + fib(2)
-> 3 + fib(2)
-> 3 + (fib (1) + fib (1))
-> 3 + (1 + fib(1))
-> 3 + (1 + 1)
-> 3 + 2
-> 5
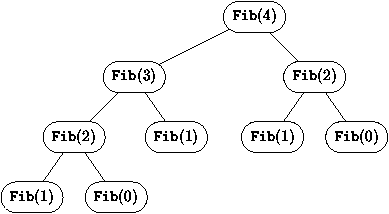
Figure 2.1 : Appels rťcursifs pour fib(4)
Il y a donc un bon nombre d'appels successifs ŗ la fonction
fib (9 pour fib(4)). Comptons le nombre d'appels
rťcursifs Rn pour cette fonction. Clairement R0 = R1 = 1, et
Rn = 1 + Rn-1 + Rn-2 pour n > 1. En posant R'n = Rn +
1, on en dťduit que R'n = R'n-1+ R'n-2 pour n > 1, R'1
= R'0 = 2. D'oý R'n = 2 ◊ fib(n), et donc le
nombre d'appels rťcursifs Rn vaut 2 ◊ fib(n) -
1, c'est ŗ dire 1, 1, 3, 5, 9, 15, 25, 41, 67, 109, 177, 287, 465,
753, 1219, 1973, 3193, 5167, 8361, 13529, 21891,... Le nombre d'appels
rťcursifs est donc trŤs ťlevť, d'autant plus qu'il existe une
mťthode itťrative simple en calculant simultanťment
fib(n) et fib(n-1). En effet, on a un
calcul linťaire simple
ś
Ť
| |
| |
Ų
Ý
| =
|
ś
Ť
| |
| |
Ų
Ý
|
ś
Ť
| |
| |
Ų
Ý
|
Ce qui donne le programme itťratif suivant
static int fib(int n) {
int u, v;
int u0, v0;
int i;
u = 1; v = 1;
for (i = 2; i <= n; ++i) {
u0 = u; v0 = v;
u = u0 + v0;
v = v0;
}
return u;
}
Pour rťsumer, une bonne rŤgle est de ne pas trop essayer de suivre
dans les moindres dťtails les appels rťcursifs pour comprendre le
sens d'une fonction rťcursive. Il vaut mieux en gťnťral comprendre
synthťtiquement la fonction. La fonction de Fibonacci est un cas
particulier car son calcul rťcursif est particuliŤrement long. Mais
ce n'est pas le cas en gťnťral. Non seulement, l'ťcriture
rťcursive peut se rťvťler efficace, mais elle est toujours plus
naturelle et donc plus esthťtique. Elle ne fait que suivre les
dťfinitions mathťmatiques par rťcurrence. C'est une mťthode de
programmation trŤs puissante.
2.1.2 La fonction d'Ackermann
La suite de Fibonacci avait une croissance exponentielle. Il existe
des fonctions rťcursives qui croissent encore plus rapidement. Le
prototype est la fonction d'Ackermann. Au lieu de dťfinir cette
fonction mathťmatiquement, il est aussi simple d'en donner la
dťfinition rťcursive en Java
static int ack(int m, int n) {
if (m == 0)
return n + 1;
else
if (n == 0)
return ack (m - 1, 1);
else
return ack (m - 1, ack (m, n - 1));
}
On peut vťrifier que
ack(0, n) = n + 1 |
ack(1, n) = n + 2 |
ack(2, n) » 2 * n |
ack(3, n) » 2 n |
|
| | |
Donc ack(5, 1) » ack(4, 4) »
265536 > 1080, c'est ŗ dire le nombre d'atomes de l'univers.
2.1.3 Rťcursion imbriquťe
La fonction d'Ackermann contient deux appels rťcursifs imbriquťs,
c'est ce qui la fait croÓtre si rapidement. Un autre exemple est la
fonction 91 de MacCarthy
static int f(int n) {
if (n > 100)
return n - 10;
else
return f(f(n+11));
}
Ainsi, le calcul de f(96) donne f(96) =
f(f(107)) = f(97) = ∑∑∑
f(100) = f(f(111)) =
f(101) = 91. On peut montrer que cette fonction vaut
91 si n £ 100 et n - 10 si n > 100. Cette fonction
anecdotique, qui utilise la rťcursivitť imbriquťe, est
intťressante car il n'est pas du tout ťvident qu'une telle
dťfinition donne toujours un rťsultat.1
Par exemple, la fonction de Morris suivante
static int g(int m, int n) {
if (m == 0)
return 1;
else
return g(m - 1, g(m, n));
}
Que vaut alors g(1, 0)? En effet, on a
g(1, 0) = g(0, g(1,
0)). Il faut se souvenir que Java passe les arguments des fonctions
par valeur.
On calcule donc toujours la valeur de l'argument avant de
trouver le rťsultat d'une fonction. Dans le cas prťsent, le calcul
de g(1,0) doit recalculer g(1, 0). Et le calcul ne
termine pas.
2.2 Indťcidabilitť de la terminaison
Les logiciens GŲdel et Turing ont dťmontrť dans les annťes 30
qu'il ťtait impossible d'espťrer trouver un programme sachant tester
si une fonction rťcursive termine son calcul. L'arrÍt d'un
calcul est en effet indťcidable.
Dans cette section, nous montrons qu'il n'existe pas de fonction
qui permette de tester si une fonction Java termine. Nous
prťsentons cette preuve sous la forme d'une petite histoire:
Le responsable des travaux pratiques d'Informatique en a
assez des programmes qui calculent indťfiniment ťcrits par des
ťlŤves peu expťrimentťs. Cela l'oblige ŗ chaque fois ŗ des
manipulations compliquťes pour stopper ces programmes. Il voit
alors dans un journal spťcialisť une publicitť:
Ne laissez plus boucler vos programmes! Utilisez notre fonction
termine(o). Elle prend comme paramŤtre le nom d'un objet et
rťpond true si la procťdure f de cet objet ne boucle pas
indťfiniment et false sinon. En n'utilisant que les procťdures
pour lesquelles termine rťpond true, vous ťvitez tous les
problŤmes de non terminaison. D'ailleurs, voici quelques exemples:
class Turing {
static boolean termine (Object o) {
// dťtermine la terminaison de o.f()
boolean resultat;
// contenu brevetť par le vendeur
return resultat;
}
}
class Facile {
void f () {
}
}
class Boucle {
void f () {
for (int i = 1; i > 0; ++i)
;
}
}
class Test {
public static void main (String args[]) {
Facile o1 = new Facile();
System.out.println (Turing.termine(o1));
Boucle o2 = new Boucle();
System.out.println (Turing.termine(o2));
}
}
pour lesquels termine(o) rťpond true puis false.
Impressionnť par la publicitť, le responsable des travaux pratiques
achŤte ŗ prix d'or cette petite merveille et pense que sa vie
d'enseignant va Ítre enfin tranquille. Un ťlŤve lui fait toutefois
remarquer qu'il ne comprend pas l'acquisition faite par
le MaÓtre avec la classe suivante:
class Absurde {
void f () {
while (Turing.termine(this))
;
}
class Test {
public static void main (String args[]) {
Absurde o3 = new Absurde();
System.out.println (Turing.termine(o3));
}
}
Si la procťdure o3.f boucle indťfiniment, alors
termine(o3) = false. Donc la boucle while de
o3.f s'arrÍte et o3.f termine. Sinon, si la procťdure
o3.f ne boucle pas indťfiniment, alors termine(o3) =
true. La boucle while prťcťdente boucle indťfiniment, et
la procťdure o3.f boucle indťfiniment. Il y a donc une
contradiction sur les valeurs possibles de termine(o3). Cette
expression ne peut Ítre dťfinie. Ayant notť le mauvais esprit de
l'ElŤve, le MaÓtre conclut qu'on ne peut dťcidťment pas faire confiance
ŗ la presse spťcialisťe!
L'histoire est presque vraie. Le MaÓtre s'appelait David Hilbert et
voulait montrer la validitť de sa thŤse par des moyens automatiques.
L'ElŤve impertinent ťtait Kurt GŲdel. Le tout se passait vers
1930. Gr‚ce ŗ GŲdel, on s'est rendu compte que toutes les
fonctions mathťmatiques ne sont pas calculables par programme. Par
exemple, il y a beaucoup plus de fonctions de N (entiers
naturels) dans N que de
programmes qui sont en quantitť dťnombrable. GŲdel, Turing, Church et
Kleene sont parmi les fondateurs de la thťorie de la calculabilitť.
Pour Ítre plus prťcis, on peut remarquer que nous demandons beaucoup ŗ
notre fonction termine, puisqu'elle prend en argument un objet
(en fait une ``adresse mťmoire''), dťsassemble peut-Ítre la procťdure
correspondante, et dťcide de sa terminaison. Sinon, elle ne peut que
lancer l'exťcution de son argument et ne peut donc tester sa
terminaison (quand il ne termine pas). Un rťsultat plus fort peut Ítre
montrť: il n'existe pas de fonction prenant en argument le source de
toute procťdure (en tant que chaÓne de caractŤres) et dťcidant de sa
terminaison. C'est ce rťsultat qui est couramment appelť
l'indťcidabilitť de l'arrÍt. Mais montrer la contradiction en Java est
alors beaucoup plus dur.
2.3 Procťdures rťcursives
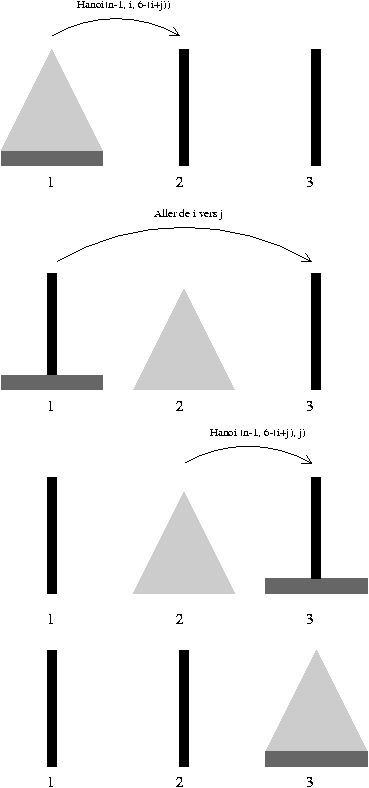
Figure 2.2 : Les tours de Hanoi
Les procťdures, comme les fonctions, peuvent Ítre rťcursives, et
comporter un appel rťcursif. L'exemple le plus classique est celui
des tours de Hanoi.
On a 3 piquets en face de soi, numťrotťs 1, 2 et
3 de la gauche vers la droite, et n rondelles de tailles toutes
diffťrentes entourant le piquet 1, formant un cŰne avec la plus
grosse en bas et la plus petite en haut. On veut amener toutes les
rondelles du piquet 1 au piquet 3 en ne prenant qu'une seule rondelle
ŗ la fois, et en s'arrangeant pour qu'ŗ tout moment il n'y ait
jamais une rondelle sous une plus grosse. La lťgende dit que les
bonzes passaient leur vie ŗ Hanoi ŗ rťsoudre ce problŤme pour
n=64, ce qui leur permettait d'attendre l'ťcroulement du temple de
Brahma, et donc la fin du monde (cette lťgende fut inventťe par le
mathťmaticien franÁais E. Lucas en 1883). Un raisonnement par
rťcurrence permet de trouver la solution en quelques lignes. Si n
£ 1, le problŤme est trivial. Supposons maintenant le problŤme
rťsolu pour n-1 rondelles pour aller du piquet i au piquet j.
Alors, il y a une solution trŤs facile pour transfťrer n rondelles
de i en j:
1- on amŤne les n-1 rondelles du haut de i sur le
troisiŤme piquet k = 6 - i - j,
2- on prend la grande rondelle en bas de i et on la met
toute seule en j,
3- on amŤne les n-1 rondelles de k en j.
Ceci s'ťcrit
static void hanoi(int n, int i, int j) {
if (n > 0) {
hanoi (n-1, i, 6-(i+j));
System.out.println (i + " -> " + j);
hanoi (n-1, 6-(i+j), j);
}
}
Ces quelques lignes de programme montrent bien comment en
gťnťralisant le problŤme, c'est-ŗ-dire aller de tout piquet i ŗ
tout autre j, un programme rťcursif de quelques lignes peut
rťsoudre un problŤme a priori compliquť. C'est la force de la
rťcursion et du raisonnement par rťcurrence. Il y a bien d'autres
exemples de programmation rťcursive, et la puissance de cette
mťthode de programmation a ťtť ťtudiťe dans la thťorie dite de
la rťcursivitť qui s'est dťveloppťe bien avant l'apparition
de l'informatique (Kleene [25], Rogers [45]).
Le mot
rťcursivitť n'a qu'un lointain rapport avec celui qui est employť
ici, car il s'agissait d'ťtablir une thťorie abstraite de la
calculabilitť, c'est ŗ dire de dťfinir mathťmatiquement les objets
qu'on sait calculer, et surtout ceux qu'on ne sait pas calculer.
Mais l'idťe initiale de la rťcursivitť est certainement ŗ
attribuer ŗ Kleene (1935).
2.4 Fractales
Considťrons d'autres exemples de programmes rťcursifs. Des exemples
spectaculaires sont le cas de fonctions graphiques fractales. Nous
utilisons les fonctions graphiques du Macintosh (cf. page
X). Un premier exemple simple est le flocon de
von Koch [11] qui est dťfini comme suit
Figure 2.3 : Flocons de von Koch
Le flocon d'ordre 0 est un triangle ťquilatťral.
Le flocon d'ordre 1 est ce mÍme triangle dont les cŰtťs sont
dťcoupťs en trois et sur lequel s'appuie un autre triangle
ťquilatťral au milieu.
Le flocon d'ordre n+1 consiste ŗ prendre le flocon d'ordre n en
appliquant la mÍme opťration sur chacun de ses cŰtťs.
Le rťsultat ressemble effectivement ŗ un flocon de neige
idťalisť. L'ťcriture du programme est laissť en exercice. On y arrive trŤs simplement en utilisant les fonctions trigonomťtriques sin et cos. Un autre exemple classique est la courbe du Dragon. La
dťfinition de cette courbe est la suivante: la courbe du Dragon
d'ordre 1 est un vecteur entre deux points quelconques P et Q, la
courbe du Dragon d'ordre n est la courbe du Dragon d'ordre n-1
entre P et R suivie de la mÍme courbe d'ordre n-1 entre R et
Q (ŗ l'envers), oý PRQ est le triangle isocŤle
rectangle en R, et R est ŗ droite du vecteur PQ. Donc, si P et
Q sont les points de coordonnťes (x, y) et (z,t), les
coordonnťes (u, v) de R sont
| u = (x + z)/2 + (t - y)/2 |
| v = (y + t)/2 - (z - x)/2 |
|
Figure 2.4 : La courbe du Dragon
La courbe se programme simplement par
static void dragon(int n, int x, int y, int z, int t) {
int u, v;
if (n == 1) {
moveTo (x, y);
lineTo (z, t);
} else {
u = (x + z + t - y) / 2;
v = (y + t - z + x) / 2;
dragon (n-1, x, y, u, v);
dragon (n-1, z, t, u, v);
}
}
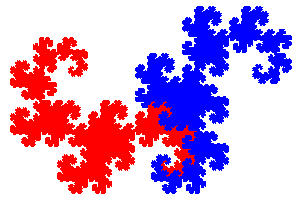
Si on calcule dragon (20, 20, 20, 220, 220), on voit
apparaÓtre un petit dragon. Cette courbe est ce que l'on obtient en
pliant 10 fois une feuille de papier, puis en la dťpliant. Une autre
remarque est que ce tracť lŤve le crayon, et que l'on prťfŤre
souvent ne pas lever le crayon pour la tracer. Pour ce faire, nous
dťfinissons une autre procťdure dragonBis qui dessine la
courbe ŗ l'envers. La procťdure dragon sera dťfinie
rťcursivement en fonction de dragon et dragonBis. De
mÍme, dragonBis est dťfinie rťcursivement en termes de
dragonBis et dragon. On dit alors qu'il y a une rťcursivitť croisťe.
static void dragon (int n, int x, int y, int z, int t) {
int u, v;
if (n == 1) {
moveTo (x, y);
lineTo (z, t);
} else {
u = (x + z + t - y) / 2;
v = (y + t - z + x) / 2;
dragon (n-1, x, y, u, v);
dragonBis (n-1, u, v, z, t);
}
}
static void dragonBis(int n, int x, int y, int z, int t) {
int u, v;
if (n == 1) {
moveTo (x, y);
lineTo (z, t);
} else {
u = (x + z - t + y) / 2;
v = (y + t + z - x) / 2;
dragon (n-1, x, y, u, v);
dragonBis (n-1, u, v, z, t);
}
}
Il y a bien d'autres courbes fractales comme la courbe de Hilbert,
courbe de Peano qui recouvre un carrť, les fonctions de Mandelbrot.
Ces courbes servent en imagerie pour faire des parcours
``alťatoires'' de surfaces, et donnent des fonds esthťtiques ŗ
certaines images.
2.5 Quicksort
Cette mťthode de tri est due ŗ C.A.R Hoare en 1960. Son principe est
le suivant. On prend un ťlťment au hasard dans le tableau ŗ
trier. Soit v sa valeur. On partitionne le reste du tableau en 2
zones: les ťlťments plus petits ou ťgaux ŗ v, et les ťlťments
plus grands ou ťgaux ŗ v. Si on arrive ŗ mettre en tÍte du
tableau les plus petits que v et en fin du tableau les plus grands,
on peut mettre v entre les deux zones ŗ sa place dťfinitive. On
peut recommencer rťcursivement la procťdure Quicksort sur chacune
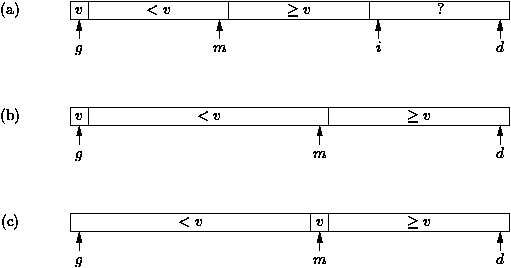
des partitions tant qu'elles ne sont pas rťduites ŗ un ťlťment. Graphiquement, on
choisit v comme l'un des ai ŗ trier. On partitionne le tableau
pour obtenir la position de la figure 2.5 (c).
Si g et d sont les bornes ŗ gauche et ŗ droite des indices du
tableau ŗ trier, le schťma du programme rťcursif est
static void qSort(int g, int d) {
if (g < d) {
v = a[g];
Partitionner le tableau autour de la valeur v
et mettre v ŗ sa bonne position m
qSort (g, m-1);
qSort (m+1, d);
}
}
Nous avons pris a[g] au hasard, toute autre valeur du
tableau a aurait convenu. En fait, la prendre vraiment au
hasard ne fait pas de mal, car Áa ťvite les problŤmes pour les
distributions particuliŤres des valeurs du tableau (par exemple
si le tableau est dťjŗ triť). Plus important,
il reste ŗ ťcrire le fragment de programme pour faire la partition.
Une mťthode ingťnieuse [6] consiste ŗ parcourir
le tableau de g ŗ d en gťrant deux indices i et m tels qu'ŗ
tout moment on a aj < v pour g < j £ m, et aj ≥ v
pour m < j < i. Ainsi
Figure 2.5 : Partition de Quicksort
m = g;
for (i = g+1; i <= d; ++i)
if (a[i] < v) {
++m;
x = a[m]; a[m] = a[i]; a[i] = x; // Echanger am et ai
}
ce qui donne la procťdure suivante de Quicksort
static void qSort(int g, int d) {
int i, m, x, v;
if (g < d) {
v = a[g];
m = g;
for (i = g+1; i <= d; ++i)
if (a[i] < v) {
++m;
x = a[m]; a[m] = a[i]; a[i] = x; // Echanger am et ai
}
x = a[m]; a[m] = a[g]; a[g] = x; // Echanger am et ag
qSort (g, m-1);
qSort (m+1, d);
}
}
Cette solution n'est pas symťtrique. La prťsentation
usuelle de Quicksort consiste ŗ encadrer la position finale de v
par deux indices partant de 1 et N et qui convergent vers la
position finale de v. En fait, il est trŤs facile de se tromper en
ťcrivant ce programme. C'est pourquoi nous avons suivi la mťthode
dťcrite dans le livre de Bentley [6].
Une mťthode trŤs efficace et symťtrique est celle qui suit,
de Sedgewick [47].
static void quickSort(int g, int d) {
int v,t,i,j;
if (g < d) {
v = a[d]; i= g-1; j = d;
do {
do
++i;
while (a[i] < v);
do
--j;
while (a[j] > v);
t = a[i]; a[i] = a[j]; a[j] = t;
} while (j > i);
a[j] = a[i]; a[i] = a[d]; a[d] = t;
quickSort (g, i-1);
quickSort (i+1, d);
}
}
On peut vťrifier que cette mťthode ne marche que si des
sentinelles ŗ gauche et ŗ droite du tableau existent, en mettant un
plus petit ťlťment que v ŗ gauche et un plus grand ŗ droite. En
fait, une maniŤre de garantir cela est de prendre toujours
l'ťlťment de gauche, de droite et du milieu, de mettre ces trois
ťlťments dans l'ordre, en mettant le plus petit des trois en a1,
le plus grand en aN et prendre le mťdian comme valeur v ŗ
placer dans le tableau a. On peut remarquer aussi comment le
programme prťcťdent rend bien symťtrique le cas des valeurs ťgales
ŗ v dans le tableau. Le but recherchť est d'avoir la partition la
plus ťquilibrťe possible. En effet, le calcul du nombre moyen CN
de comparaisons empruntť ŗ [47] donne C0 = C1 = 0,
et pour N ≥ 2,
| CN = N + 1 + |
| |
| (Ck-1 + CN-k) |
D'oý par symťtrie
En soustrayant, on obtient aprŤs simplification
N CN = (N+1) CN-1 + 2 N
En divisant par N(N+1)
En approximant
D'oý le rťsultat
CN » 1,38 N log2 N
Quicksort est donc trŤs efficace en moyenne. Bien sŻr, ce tri peut
Ítre en temps O(N2), si les partitions sont toujours
dťgťnťrťes par exemple pour les suites monotones croissantes ou
dťcroissantes. C'est un algorithme qui a une trŤs petite constante
(1,38) devant la fonction logarithmique. Une bonne technique consiste
ŗ prendre Quicksort pour de gros tableaux, puis revenir au tri par
insertion pour les petits tableaux (£ 8 ou 9 ťlťments).
Le tri par Quicksort est le prototype de la mťthode de programmation
Divide and Conquer (en franÁais ``diviser pour rťgner'').
En
effet, Quicksort divise le problŤme en deux (les 2 appels rťcursifs)
et recombine les rťsultats gr‚ce ŗ la partition initialement faite
autour d'un ťlťment pivot. Divide and Conquer sera la mťthode
chaque fois qu'un problŤme peut Ítre divisť en morceaux plus
petits, et que l'on peut obtenir la solution ŗ partir des rťsultats
calculťs sur chacun des morceaux. Cette mťthode de programmation est
trŤs gťnťrale, et reviendra souvent dans le cours. Elle suppose
donc souvent plusieurs appels rťcursifs et permet souvent de passer
d'un nombre d'opťrations linťaire O(n) ŗ un nombre d'opťrations
logarithmique O(log n).
2.6 Le tri par fusion
Une autre procťdure rťcursive pour faire le tri est le tri par
fusion (ou par interclassement). La mťthode provient du tri sur
bande magnťtique (pťriphťrique autrefois fort utile des
ordinateurs). C'est aussi un exemple de la mťthode Divide and
Conquer. On remarque d'abord qu'il est aisť de faire
l'interclassement entre deux suites de nombres triťs dans l'ordre
croissant. En effet, soient Š a1, a2, ... aM Ů et
Š b1, b2, ... bN Ů ces deux suites. Pour obtenir,
la suite interclassťe Š c1, c2, ... cM+N Ů des
ai et bj, il suffit de faire le programme suivant. (On
suppose que l'on met deux sentinelles aM+1 = • et
bN+1 = • pour ne pas compliquer la structure du programme.)
int[] a = new int[M+1],
b = new int[N+1],
c = new int[M+N];
int i = 0, j = 0;
a[M+1] = b[N+1] = Integer.MAX_VALUE;
for (int k = 0; k < M+N; ++k)
if (a[i] <= b[j]) {
c[k] = a[i];
++i;
} else {
c[k] = b[j];
++j;
}
Successivement, ck devient le minimum de ai et bj
en dťcalant l'endroit oý l'on se trouve dans la suite a ou b
selon le cas choisi. L'interclassement de M et N ťlťments se
fait donc en O(M+N) opťrations. Pour faire le tri fusion, en
appliquant Divide and Conquer,
on trie les deux moitiťs de la
suite Š a1, a2, ... aN Ů ŗ trier, et
on interclasse les deux moitiťs triťes. Il y a toutefois une
difficultť car on doit copier dans un tableau annexe les 2
moitiťs ŗ trier, puisqu'on ne sait pas faire l'interclassement en
place. Si g et d sont les bornes ŗ gauche et ŗ droite des indices du tableau ŗ trier, le tri fusion est donc
static void TriFusion(int g, int d) {
int i, j, k, m;
if (g < d) {
m = (g + d) / 2;
TriFusion (g, m);
TriFusion (m + 1, d);
for (i = m; i >= g; --i)
b[i] = a[i];
for (j = m+1; j <= d; ++j)
b[d+m+1-j] = a[j];
i = g; j = d;
for (k = g; k <= d; ++k)
if (b[i] < b[j]) {
a[k] = b[i]; ++i;
} else {
a[k] = b[j]; --j;
}
}
}
La recopie pour faire l'interclassement se fait dans un
tableau b de mÍme taille que a. Il y a une petite
astuce en recopiant une des deux moitiťs dans l'ordre inverse, ce qui
permet de se passer de sentinelles pour l'interclassement, puisque
chaque moitiť sert de sentinelle pour l'autre moitiť. Le tri par
fusion a une trŤs grande vertu. Son nombre d'opťrations CN est
tel que CN = 2 N + 2 CN/2, et donc CN = O(N log N). Donc le
tri fusion est un tri qui garantit un temps N log N, au prix d'un
tableau annexe de N ťlťments. Ce temps est rťalisť quelle que soit
la distribution des donnťes, ŗ la diffťrence de QuickSort.
Plusieurs problŤmes se posent immťdiatement: peut on faire mieux?
Faut-il utiliser ce tri plutŰt que QuickSort?
Nous rťpondrons plus tard ``non'' ŗ la premiŤre question, voir
section 1. Quant ŗ la deuxiŤme question, on
peut remarquer que si ce tri garantit un bon temps, la constante
petite devant N log N de QuickSort fait que ce dernier est souvent
meilleur. Aussi, QuickSort utilise moins de mťmoire annexe, puisque
le tri fusion demande un tableau qui est aussi important que celui ŗ
trier. Enfin, on peut remarquer qu'il existe une version itťrative du
tri par fusion en commenÁant par trier des sous-suites de longueur 2,
puis de longueur 4, 8, 16, ....
2.7 Programmes en Caml
(* Fibonaci, voir page X *)
let rec fib n =
if n <= 1 then 1
else fib (n - 1) + fib ( n - 2);;
(* Factorielle, voir page X *)
let rec fact n =
if n <= 1 then 1
else n * fact (n - 1);;
(* Triangle de Pascal, voir page X *)
let rec C n p =
if n = 0 || p = n then 1
else C (n - 1) (p - 1) + C (n - 1) p;;
(* Fibonaci itťratif, voir page X *)
let fib n =
let u = ref 1 and v = ref 1 in
for i = 2 to n do
let u0 = !u and v0 = !v in
u := u0 + v0;
v := u0
done;
!u;;
(* Le mÍme en style fonctionnel *)
let fib n =
let rec fib_aux k u v =
if k > n then u
else fib_aux (k + 1) (u + v) u in
fib_aux 2 1 1;;
(* La fonction d'Ackermann, voir page X *)
let rec ack m n =
if m = 0 then n + 1 else
if n = 0 then ack (m - 1) 1 else
ack (m - 1) (ack m (n - 1));;
(* La fonction 91, voir page X *)
let rec f91 n =
if n > 100 then n - 10
else f91 (f91 (n + 11));;
(* La fonction de Morris, voir page X *)
let rec g m n =
if m = 0 then 1
else g (m - 1) (g m n);;
(* Les tours de Hanoi, voir page X *)
let rec hanoi n i j =
if n > 0 then begin
hanoi (n - 1) i (6 - (i + j));
printf "%d -> %d\n" i j;
hanoi (n - 1) (6 - (i + j)) j;
end;;
#open "graphics";;
open_graph "";;
let rec dragon n x y z t =
if n = 1 then begin
moveto x y;
lineto z t
end else begin
let u = (x + z + t - y) / 2
and v = (y + t - z + x) / 2 in
dragon (n - 1) x y u v;
dragon (n - 1) z t u v
end;;
(* La courbe du dragon, voir page X *)
let rec dragon n x y z t =
if n = 1 then begin
moveto x y;
lineto z t
end else begin
let u = (x + z + t - y) / 2
and v = (y + t - z + x) / 2 in
dragon (n - 1) x y u v;
dragon_bis (n - 1) u v z t
end
and dragon_bis n x y z t =
if n = 1 then begin
moveto x y;
lineto z t
end else begin
let u = (x + z - t + y) / 2
and v = (y + t + z - x) / 2 in
dragon (n - 1) x y u v;
dragon_bis (n - 1) u v z t
end;;
clear_graph();;
dragon 15 120 120 50 50;;
(* Quicksort, voir page X *)
let rec qsort g d =
if g < d then begin
let v = a.(g)
and m = ref g in
for i = g + 1 to d do
if a.(i) < v then begin
m := !m + 1;
let x = a.(!m) in
a.(!m) <- a.(i); a.(i) <- x
end
done;
let x = a.(!m) in
a.(!m) <- a.(g); a.(g) <- x;
qsort g (!m - 1);
qsort (!m + 1) d
end;;
(* Quicksort, voir page X *)
let rec quicksort g d =
if g < d then begin
let v = a.(d)
and t = ref 0
and i = ref (g - 1)
and j = ref d in
while j > i do
incr i;
while a.(!i) < v do incr i done;
decr j;
while a.(!j) > v do decr j done;
t := a.(!i);
a.(!i) <- a.(!j);
a.(!j) <- !t
done;
a.(!j) <- a.(!i);
a.(!i) <- a.(d);
a.(d) <- !t;
quicksort g (!i - 1);
quicksort (!i + 1) d
end;;
(* Tri fusion, voir page X *)
let b = make_vect n 0;;
let rec tri_fusion g d =
if g < d then begin
let m = (g + d) / 2 in
tri_fusion g m;
tri_fusion (m + 1) d;
for i = m downto g do
b.(i) <- a.(i) done;
for i = m + 1 to d do
b.(d + m + 1 - i) <- a.(i) done;
let i = ref g and j = ref d in
for k = g to d do
if b.(!i) < b.(!j) then begin
a.(k) <- b.(!i); incr i
end else begin
a.(k) <- b.(!j); decr j
end
done
end;;
- 1
- Certains systŤmes
peuvent donner des rťsultats partiels, par exemple le systŤme SYNTOX
de FranÁois Bourdoncle qui arrive ŗ traiter le cas de cette
fonction