Dans cette page nous étudions la structure de l'implémentation de Pavot. Le langage utilisé est Java qui offre tous les avantages des langages objets (réutilisabilité, polymorphismes...) et de bonnes bibliothčques d'interfaçage.
Architecture
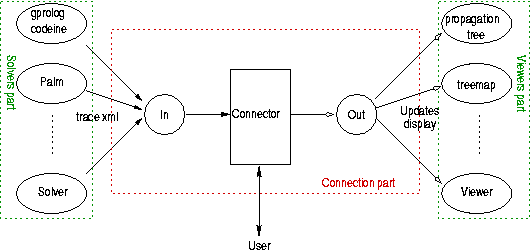 |
Comme on peut le voir sur ce schéma simplifié, Pavot a été conçu comme un composant intermédiaire entre des solveurs et des viewers (ŕ l'intérieur des pointillés rouges: "Connection part"). En théorie les entrées et sorties peuvent ętre totalement hétérogénes. C'est le cas pour les solveurs qui n'ont comme contrainte que de sortir une trace XML respectant la DTD OADymPPaC. Par contre, dans la pratique, les visualiseurs en sortie sont intégrés directement dans Pavot. Ceci est du essentiellement ŕ un manque de protocole de visualisation (par exemple on aimerait envoyer en sortie un arbre de recherche, un tableau de données ... interprétable par un maximum d'outil de visualisation). Le connecteur se charge de relier toutes les parties entre elles ainsi que de gérer les différentes requętes de l'utilisateur. Dans l'état d'avancement actuel le pilotage de la trace ŕ partir des visualiseurs n'est pas possible, ceci en raison du faible avancement ŕ ce sujet du projet OADymPPaC.
| [Solver manager] | [Connector] | [Viewer Manager] | [Requętes] |
-
Solver manager
Le solver manager est basé essentiellement sur le travail de Jean-Daniel Fekete et Mohamad Ghoniem. Il est constitué d'un parser XML (SAX) et d'un générateur d'évenements simulant le fonctionnement d'un solveur. Ceci permet d'avoir ŕ la fois un filtrage de la trace et une restructuration des données reçues sous la forme de "méta-événements" (les différents événements propagation sont réunis en un seul par exemple).
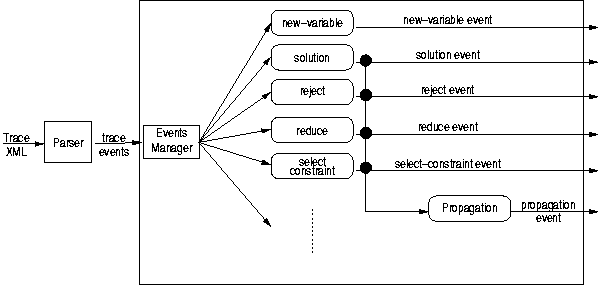
Schéma partiel du solver manager
Pavot est capable de se connecter ŕ une socket émettant la trace XML ou de lire la trace directement dans un fichier (*.xml ou *.xml.gz).
-
Connector
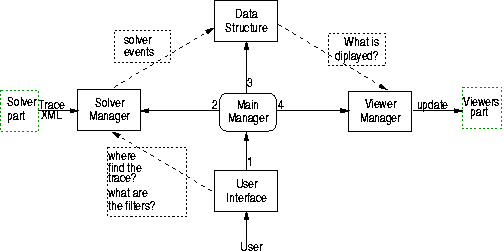
Schéma du connecteur: les flęches numérotées donnent l'ordre d'instanciation de chaque entité, certaine ne pouvant ętre instancier avant d'autres ("view manager" a besoin de "data struct").
Le connecteur est l'architecture principale permettant de relier les différentes entités, chaque entité étant déconnecté le plus possible des autres afin de faciliter au maximum les extensions futures. Il est apparu important entre autre de bien séparer la partie structure de données (arbre de recherche, de propagation, tableau contraintes/contraintes, variables/valeurs...) de la partie visualisation. La structure de donnée est branchée aux différents évenements du solveur qui lui donnent les informations nécessaire pour sa construction. On peut ainsi avoir plusieurs arbres avec des sémantiques différentes, un arbre de recherche classique(?), un arbre de propagation (ŕ chaque noeud on a l'information sur le nombre de propagation avec raffinement plus ou moins grand) ou encore un arbre prolog (?). Selon les vues et le niveau d'information demandés on instanciera uniquement les structures de données nécessaires et une męme structure peut ętre utilisée par différent visualiseur, ce qui permet d'économiser de l'espace-temps.
Voir : [Structure de données]-[Requętes]
La partie interface utilisateur permet de spécifier les vues et le filtrage désirés, et de se connecter ŕ une sortie de trace d'un solveur ou de charger un fichier.
-
Viewer manager
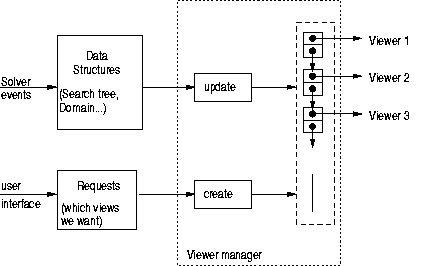
Schéma du viewer manager
-
Requętes de filtrage